pytorch日积月累5-pytorch数据读取机制
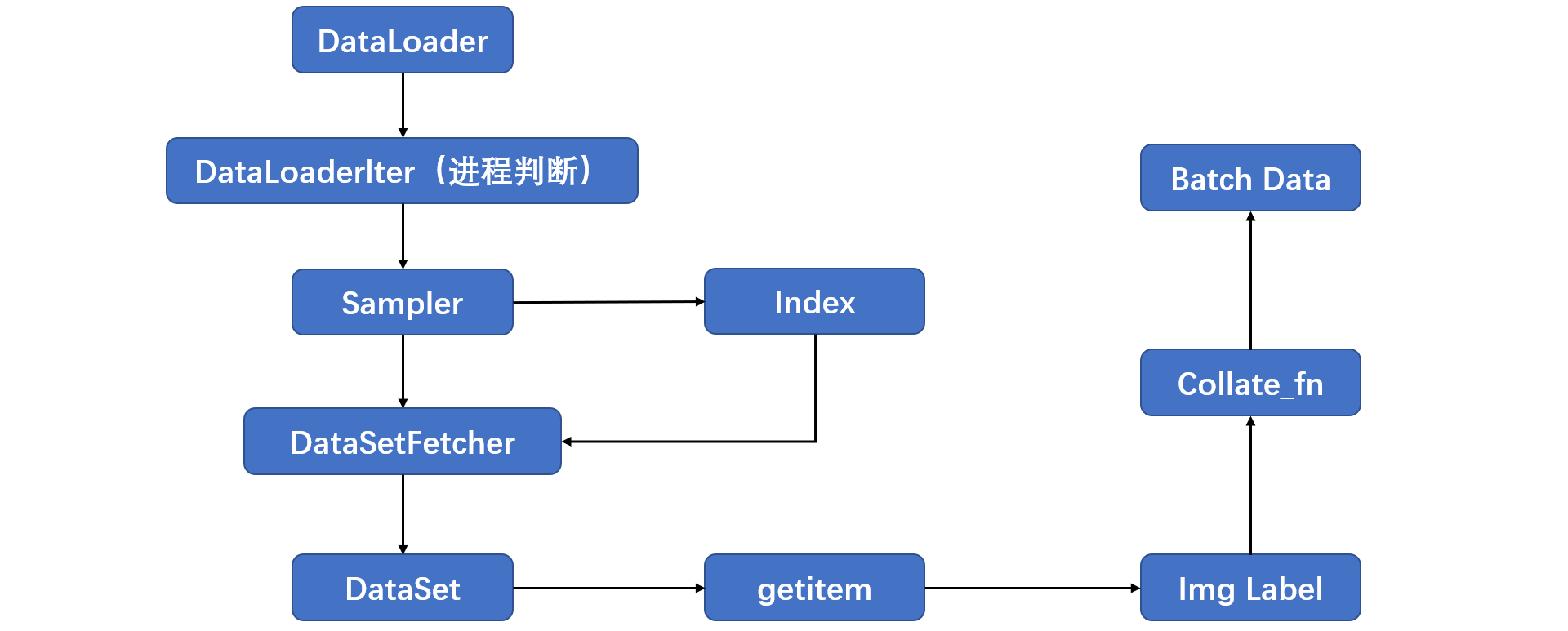
DataLoader和DataSet
torch.utils.data.DataLoader- 功能:构建可迭代的数据装载器
1 | #构建可迭代的数据装载器 |
- epoch: 所有训练样本都已输入到模型中,称为一个epoch
- iteration:一批样本输入到模型中,称之为一个iteration
- batchsize:批大小,决定一个epoch有多少个iteration
【举例】
- 样本总数:80, Batchsize:8 ,则1 Epoch = 10 Iteration
- 样本总数:87, Batchsize:8
- 1 Epoch = 10 Iteration when
drop_last = True - 1 Epoch = 11 Iteration when
drop_last = False
- 1 Epoch = 10 Iteration when
torch.utils.data.Dataset
- 功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写
__getitem__() getitem:接收一个索引,返回一个样本
1 | class Dataset(object): |
数据读取:
- 读哪些数据——sampler输出的index
- 从哪里读数据——DataSet中的data_dir
- 怎么读数据——Dataset中的getitem
1 | train_data = RDataset(data_dir=train_dir, transform=train_transform) |
数据读取的过程: