CVbaseline-AlexNet笔记
AlexNet : ImageNet Classification with Deep Convolutional Neural Networks
模型结构设计:ReLU,LRN,Overlapping pooling,双GPU训练
减轻过拟合:图像增强,DropOut
ILSVRC
卷积核可视化
1.研究背景
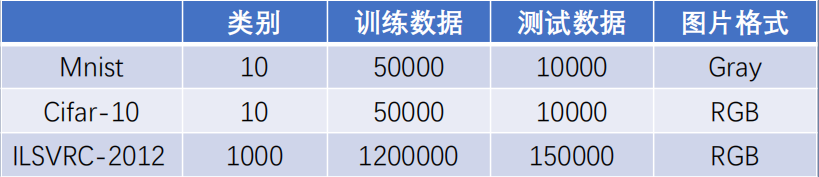
常见的图像分类数据集:
ILSVRC:大规模图像识别挑战赛
ImageNet Large Scale Visual Recognition Challenge 是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展。
比赛项目涵盖:
图像分类(Classification)
目标定位(Object localization)
目标检测(Object detection)
视频目标检测(Object detection from video)
场景分类(Scene classification)
场景解析(Scene parsing)
竞赛中脱颖而出大量经典模型: Alexnet,VGG,GoogleNet,ResNet,DenseNet等
ImageNet 数据集包含 21841 个类别,14,197,122张图片其通过WordNet对类别进行分组,使数据集的语义信息更合理,非常适合图像识别ILSVRC-2012 从ImageNet中挑选1000类的1,200,000张作为训练集。
Top5 error的含义:

AlexNet网络的成果:

2.研究成果和意义
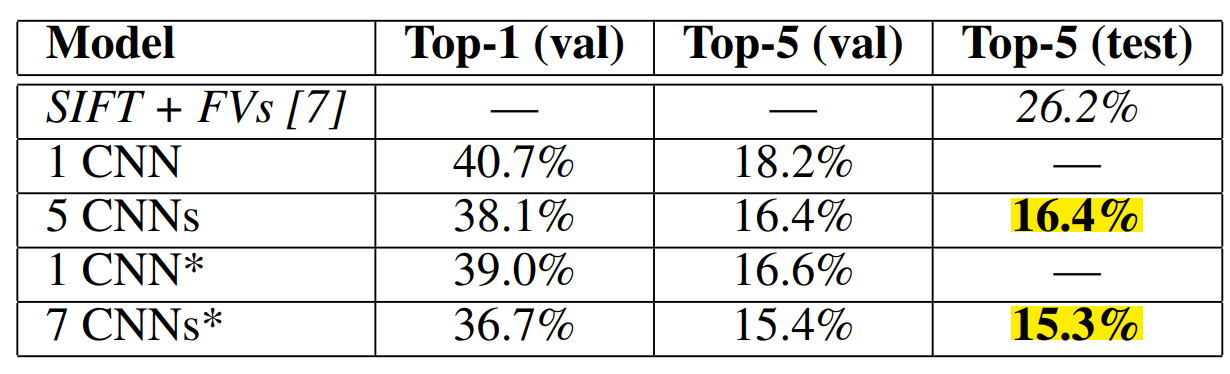
AlexNet在ILSVRC-2012以超出第二名10.9个百分点夺冠
SIFT+FVS:ILSVRC-2012 分类任务第二名
1CNN :训练一个AlexNet
5CNNs :训练五个AlexNet取平均值
1CNN*在最后一个池化层之后,额外添加第六个卷积层,并使用ImageNet 2011(秋)数据集上预训练
7CNNs* 两个预训练微调,与5CNNs取平均值
历史意义:
- 拉开卷积神经网络统计计算机视觉的序幕
- 加速计算机视觉应用落地
这篇论文的重大历史意义在于:AlexNet拉开卷积神经网络统治计算机视觉的序幕,加速计算机视觉应用落地。使研究问题的方法由机器学习领域的特征提取—>特征筛选—->输入分类器的过程,逐渐进化到深度学习领域的特征工程和分类集成为一体。
在安防领域的人脸识别、行人检测、智能视频分析、行人跟踪等,交通领域的交通场景物体识别、车辆计数、逆行检测、车牌检测与识别,以及互联网领域的基于内容的图像检索、相册自动归类等方面有着广泛的应用。
3.论文结构
摘要 Abstract:介绍背景及提出AlexNet模型,获得ILSVRC-2012冠军
Introduction:研究的成功得益于大量数据及高性能GPU;介绍本论文主要贡献
The Dataset:ILSVRC数据集简介;图片预处理细节
The Architecture:AlexNet网络结构及其内部细节:ReLU、GPU、LRN、Overlapping,Pooling
Reducing Overfitting:防过拟合技术,数据增强和dropout
Details of learning:实验参数设置:超参调整,权重初始化
Results:AlexNet比赛指标、成绩及其详细设置
Qualitative Evaluations:实验探究,分析卷积核模式,模型输出合理性,高级特征的相似性
Discussion:强调网络结构之间的强关联,提出进一步研究方向
4.摘要
在ILSVRC-2010的120万张图片上训练深度卷积神经网络,获得最优结果,top-1和top-5error分别为 37.5%, 17%
该网络(AlexNet)由5个卷积层和3个全连接层构成,共计6000万参数,65万个神经元
为加快训练,采用非饱和激活函数——ReLU,采用GPU训练
为减轻过拟合,采用Dropout
基于以上模型及技巧,在ILSVRC-2012以超出第二名10.9个百分点成绩夺冠
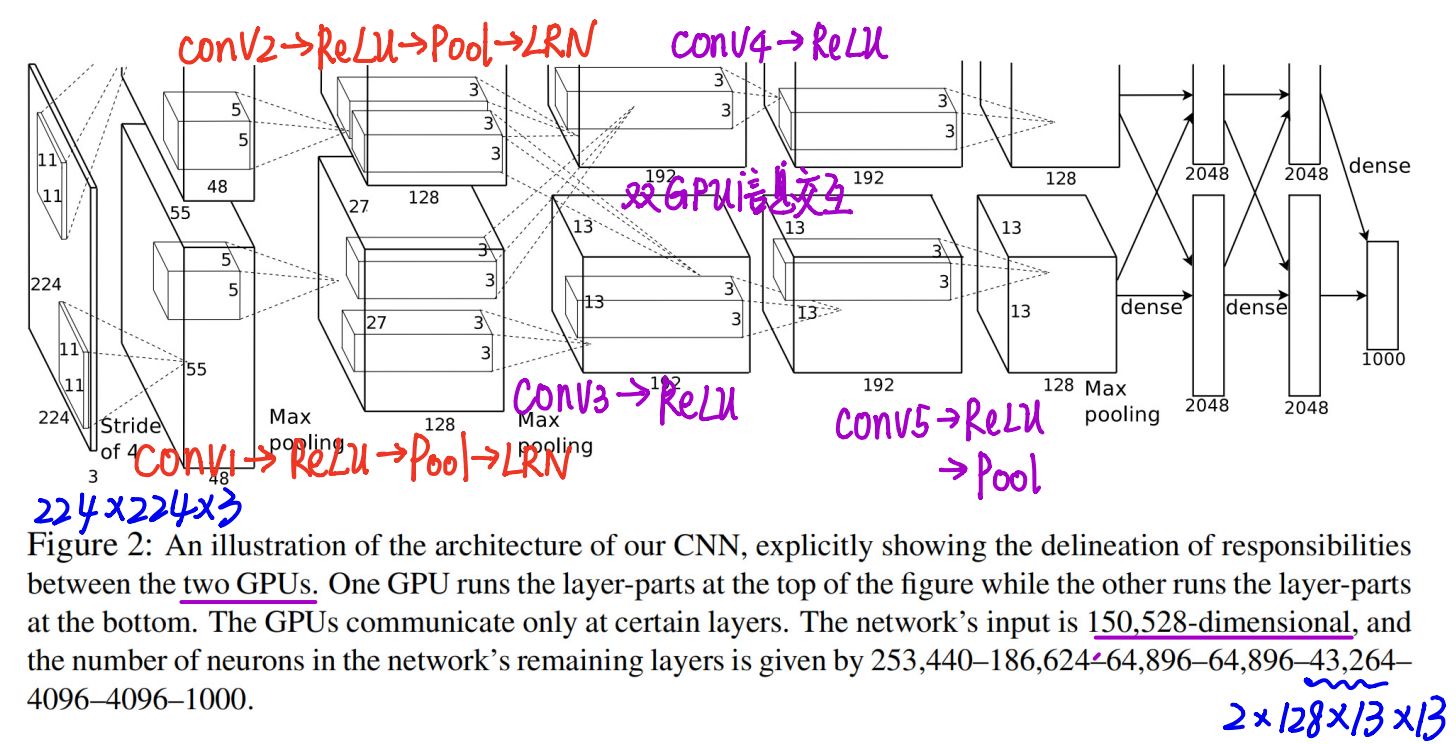
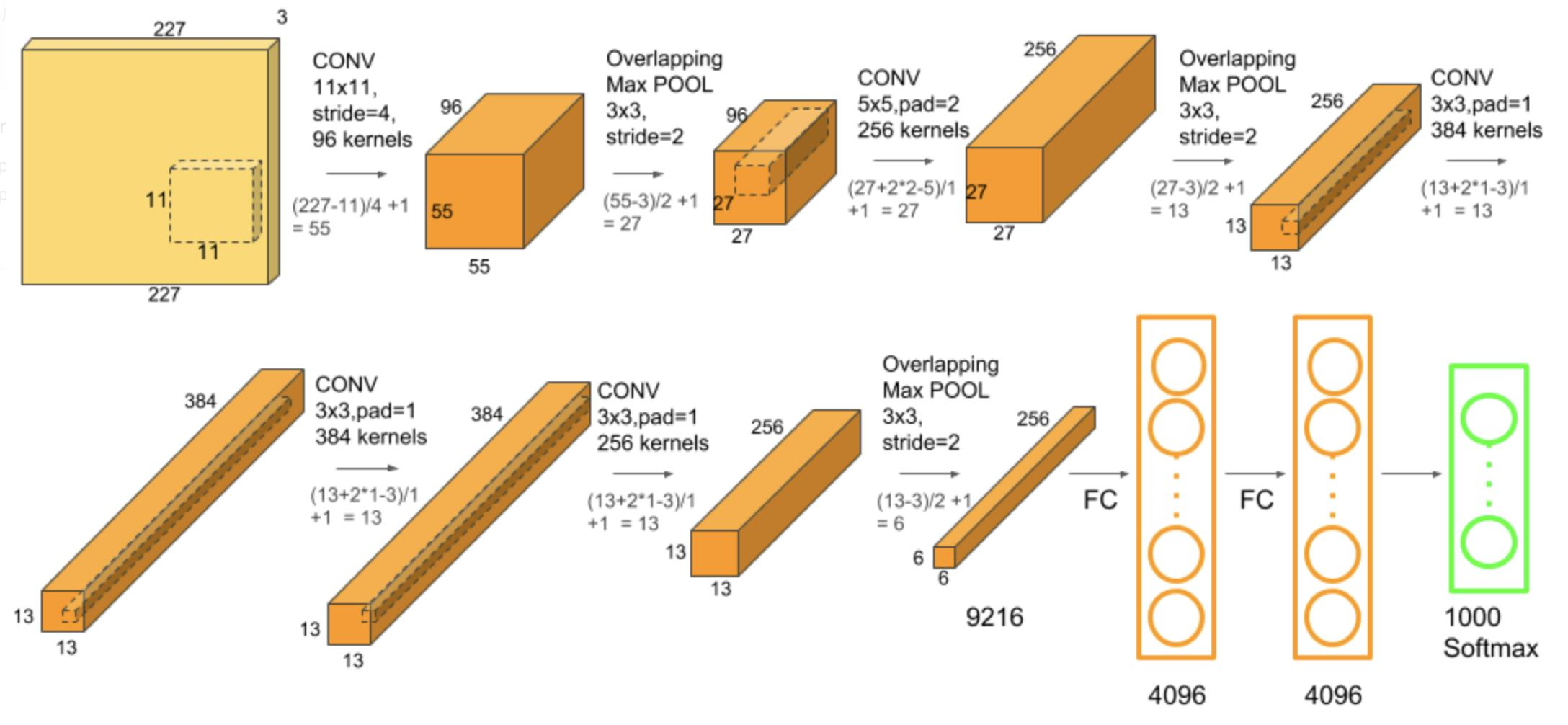
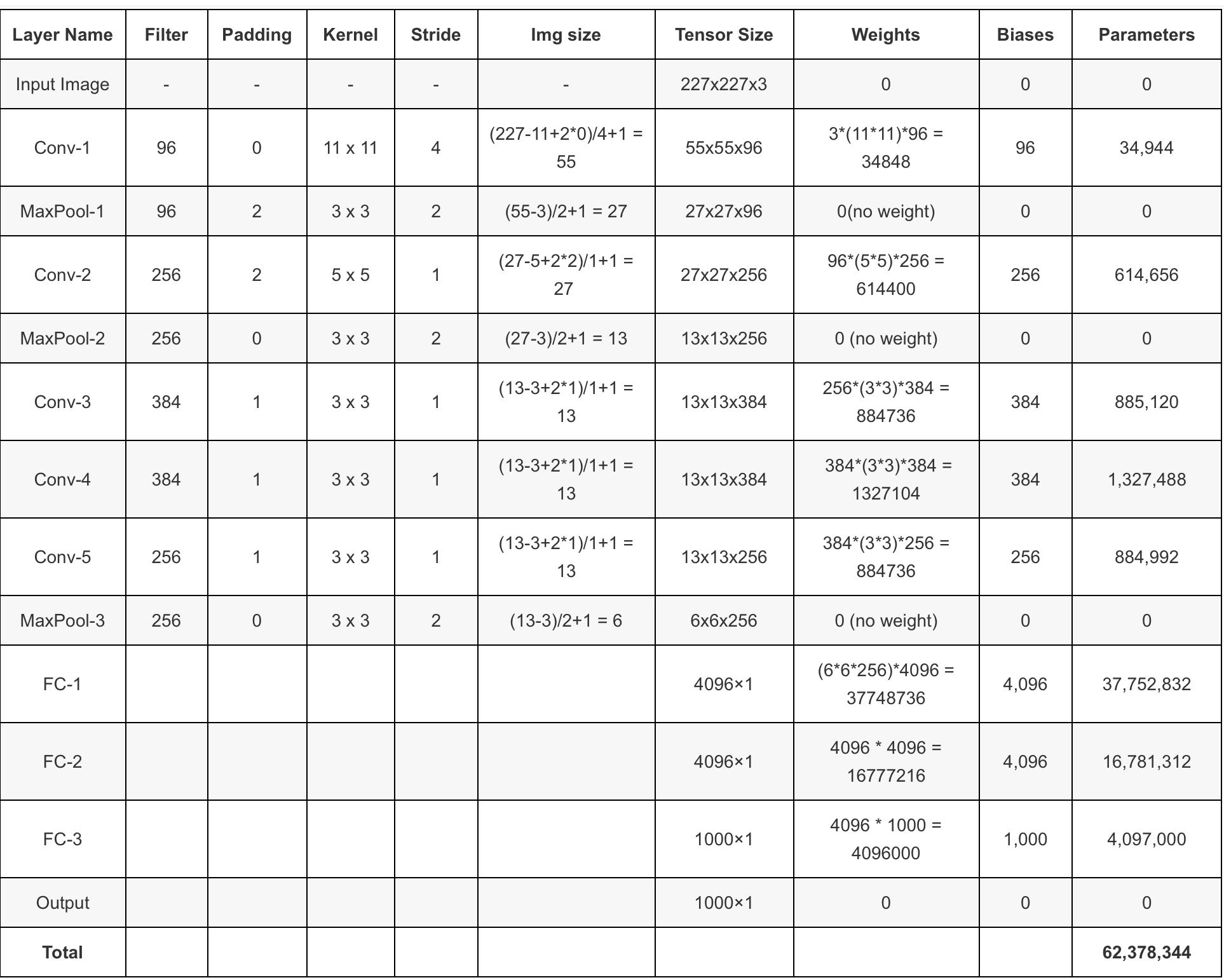
5.网络结构
论文3.5部分
网络模型结构:
卷积输出特征图:
$ F_{\text {in }}$输入特征图尺寸,$k$表示kernel size,$p$表示padding,$s$表示步长
连接数量计算公式:$F_{i} \times\left(K_{s} \times K_{s}\right) \times K_{n}+K_{n}$,6000万参数的来源:
AlexNet 结构特点:

- The Architecture
- ReLU Nonlinearity
- Training on Multiple GPUs
- Local Response Normalization
- Overlapping Pooling
5.1RELU
ReLU Nonlinearity Relu优点:
使网络训练更快
防止梯度消失(弥散)
使网络具有稀疏性
sigmod激活函数:${y}=\frac{1}{1+e^{-x}}$,其梯度表示为:$y’=y\times(1-y)$
Relu激活函数:$\mathbf{y}=\max (\mathbf{0}, x)$,梯度表示:$y^{\prime}=\left\{\begin{array}{cc}
1, & x>0 \\
\text { undefined, } & x=0 \\
0, & x<0
\end{array}\right.$
5.2LRN
Local Response Normalization
局部响应标准化:有助于AlexNet泛化能力的提升受真实神经元侧抑制(lateral inhibition)启发。
侧抑制:细胞分化变为不同时,它会对周围细胞产生抑制信号,阻止它们向相同方向分化,最终表现为细胞命运的不同。
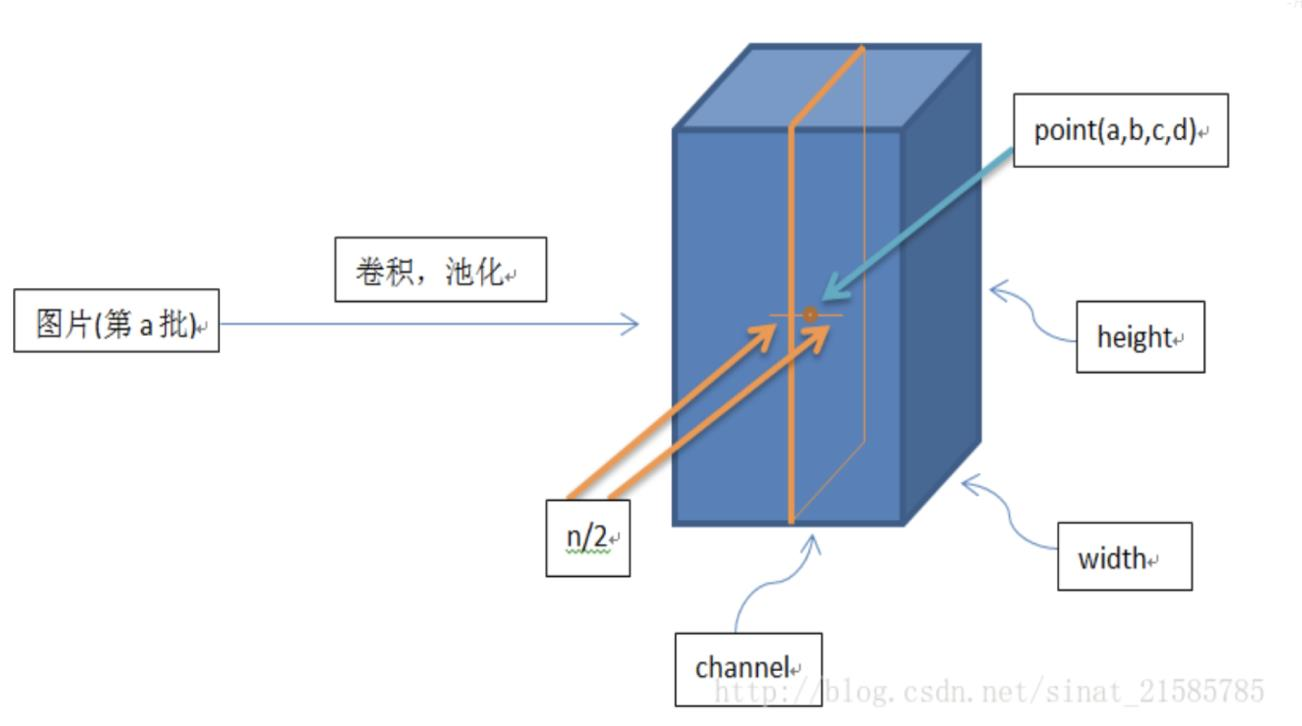
$k = 2, n = 5$, $\alpha = 10^{−4}$, and $\beta = 0.75$
$i$:代表通道 channel
$j$:平方累加索引,代表从j~i的像素值平方求和
$x,y$:像素的位置,公式中用不到
$a$:代表feature map里面的 i 对应像素的具体值
$N$:每个feature map里面最内层向量的列数
$k$:超参数,由原型中的blas指定
$α$:超参数,由原型中的alpha指定
$n/2$:超参数,由原型中的deepth_radius指定
$β$:超参数,由原型中的belta指定
5.3Overlapping Pooling
重叠池化,池化过程中会有一部分的重叠
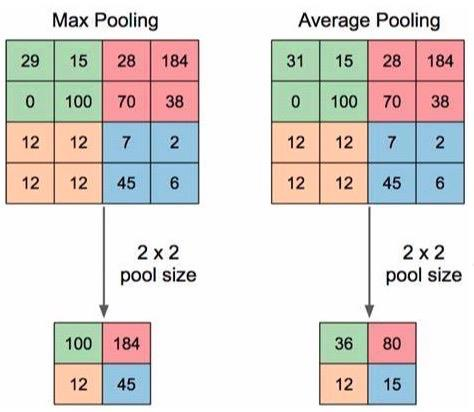
alexnet中提出和使用。
相对于传统的no-overlapping pooling,采用Overlapping Pooling不仅可以提升预测精度,同时一定程度上可以减缓过拟合。
相比于正常池化(步长s=2,窗口z=2) 重叠池化(步长s=2,窗口z=3) 可以减少top-1, top-5分别为0.4% 和0.3%;重叠池化可以避免过拟合。
6.训练技巧
6.1Data Augmentation
数据增强
方法一:针对位置
训练阶段:
图片统一缩放至256*256
随机位置裁剪出224*224区域
- 随机进行水平翻转
测试阶段:
图片统一缩放至256*256
裁剪出5个224*224区域
均进行水平翻转,共得到10张224*224图片
方法二:针对颜色

进行主成分分析,进行RGB的图像扰动
通过PCA方法修改RGB通道的像素值,实现颜色扰动,效果有限,仅在top-1提升1个点(top-1 acc约62.5%)
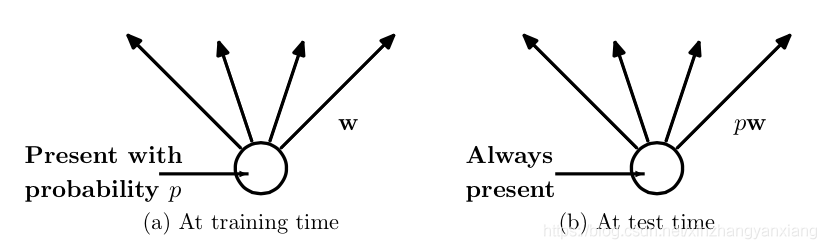
6.2DropOut
Dropout:随机失活
随机:dropout probability (eg:p=0.5)
失活:weight = 0
注意事项:训练和测试两个阶段的数据尺度变化
测试时,神经元输出值需要乘以 p
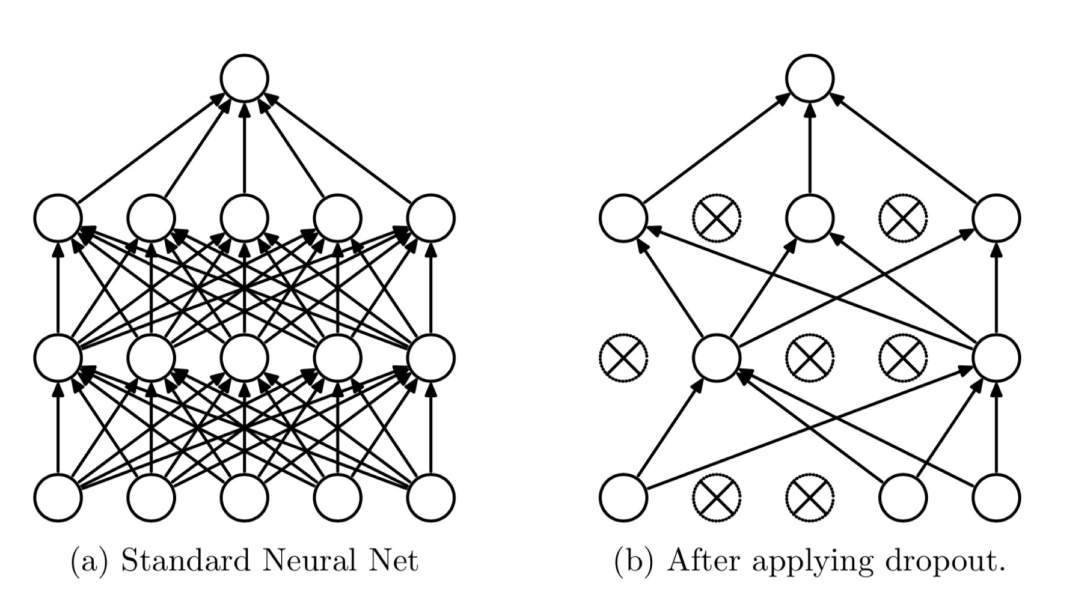
因而,对于一个有N个节点的神经网络,有了dropout后,就可以看做是$2^n$个模型的集合了,但此时要训练的参数数目却是不变的,这就解脱了费时的问题。
而为了达到ensemble的特性,有了dropout后,神经网络的训练和预测就会发生一些变化。
对应的公式变化如下如下:
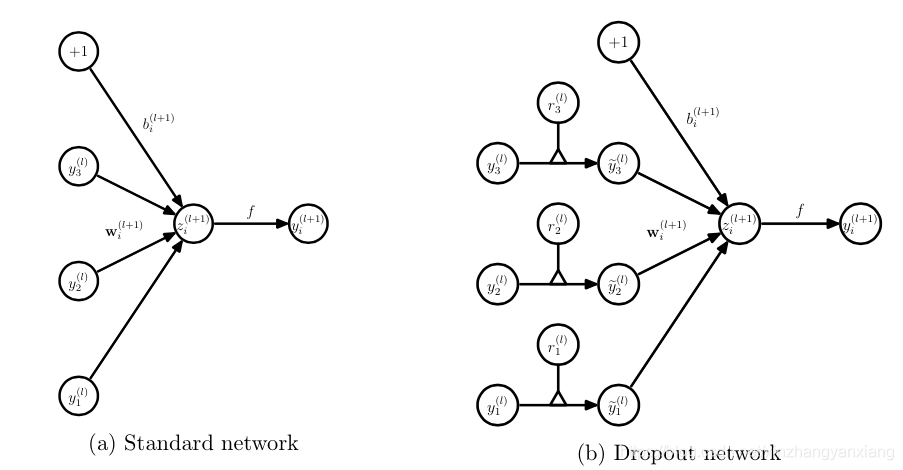
- 没有dropout的神经网络:
- 有dropout的神经网络:
- 测试层面:预测的时候,每一个单元的参数要预乘以p。
7.实验结果及分析
Qualitative Evaluations 卷积核可视化
• 卷积核呈现出不同的频率、方向和颜色
• 两个GPU还呈现分工学习(一个负责频率方向,一个负责颜色)

This kind of specialization occurs during every run and is independent of any particular random weight initialization (modulo a renumbering of the GPUs).
即便是随机的参数设置,GPU也呈现出分工的模式。
Qualitative Evaluations特征的相似性
相似图片的第二个全连接层输出特征向量的欧式距离相近
启发:
- 可用AlexNet提取高级特征进行图像检索、图像聚类、图像编码

8.总结
关键点
• 大量带标签数据——ImageNet
• 高性能计算资源——GPU
• 合理算法模型——深度卷积神经网络
创新点
• 采用ReLu加快大型神经网络训练
• 采用LRN提升大型网络泛化能力
• 采用Overlapping Pooling提升指标
• 采用随机裁剪翻转及色彩扰动增加数据多样性
• 采用Drpout减轻过拟合
启发点
• 深度与宽度可决定网络能力
Their capacity can be controlled by varying their depth and breadth.
• 更强大GPU及更多数据可进一步提高模型性能
All of our experiments suggest that our results can be improved simply by waiting for faster GPUs and bigger datasets to become available.
• 图片缩放细节,对短边先缩放
Given a rectangular image, we first rescaled the image such that the shorter side was of length 256, and then cropped out the central 256×256 patch from the resulting image.
• ReLU不需要对输入进行标准化来防止饱和现象,即说明sigmoid/tanh激活函数有必要对输入进行标准化
ReLUs have the desirable property that they do not require input normalization to prevent them from saturating
• 卷积核学习到频率、方向和颜色特征
The network has learned a variety of frequency- and orientation-selective kernels, as well as various colored blobs.
• 相似图片具有“相近”的高级特征
If two images produce feature activation vectors with a small Euclidean separation, we can say that the higher levels of the neural network consider them to be similar.
• 图像检索可基于高级特征,效果应该优于基于原始图像
This should produce a much better image retrieval method than applying autoencoders to the raw pixels.
• 网络结构具有相关性,不可轻易移除某一层
It is notable that our network’s performance degrades if a single convolutional layer is removed.
• 采用视频数据,可能有新突破
Ultimately we would like to use very large and deep convolutional nets on video sequences.
9代码
9.1关键函数
1.torch.topk:用于寻找top-5的预测
功能:找出前k大的数据,及其索引序号
input:张量 k:决定选取k个值 dim:索引维度
返回:Tensor:前k大的值 LongTensor:前k大的值所在的位置
1 | torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) |
2.FiveCrop,TenCrop
1 | transforms.FiveCrop(size) |
功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片,TenCrop对这5张图片进行水平或者垂直镜像获得10张图片。
size:所需裁剪图片尺寸 vertical_flip:是否垂直翻转
3.torchvision.utils.make_grid
1 | make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0) |
- tensor:图像数据,
B*C*H*W形式 - nrow:行数(列数自动计算)
- padding:图像间距(像素单位)
- normalize:是否将像素值标准化
- range:标准化范围
- scale_each:是否单张图维度标准化
- pad_value:padding的像素值