pytorch日积月累8-权值初始化
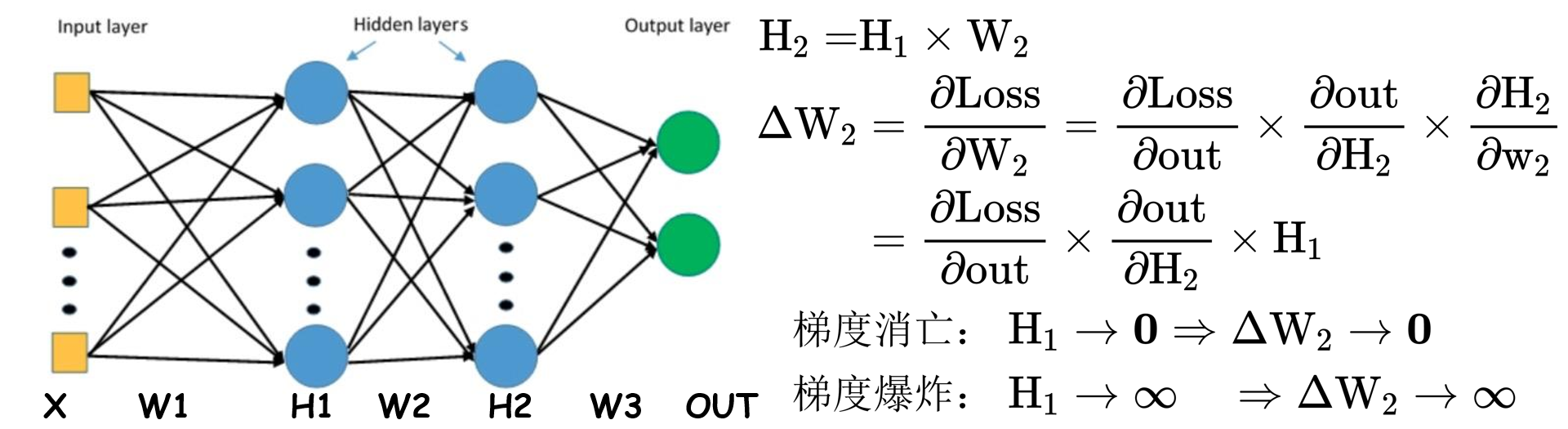
1.梯度消亡和梯度爆炸
- ${D}({X} \times {Y})={D}({X}) \times {D}({Y})+{D}({X}) \times[E({Y})]^{2}+{D}({Y}) \times[{E}({X})]^{2}$
- 若$E({X})=0, {E}({Y})=0$,则有$\mathrm{D}(\mathrm{X} \times \mathrm{Y})=\mathrm{D}(\mathrm{X}) \times \mathrm{D}(\mathrm{Y})$
已知$H_1$层输出的结果$\mathrm{H}_{11}=\sum_{i=0}^{n} X_{i} \times W_{1 i}$,根据$\quad \mathrm{D}(\mathrm{X} \times \mathrm{Y})=\mathrm{D}(\mathrm{X}) \times \mathrm{D}(\mathrm{Y})$,可以得到:
可以发现对于神经网络,每一层的标准差都变为原来的$\sqrt{n}$倍。
1 | def initialize(self): |
2.Xavier初始化
带有激活函数时如何进行初始化:
方差一致性:保持数据尺度维持在恰当范围,通常方差为1
激活函数:饱和函数,如Sigmoid,Tanh
1 | #利用公式进行的初始化方法 |
1 | #nn模块中的Xavier初始化方法 |
3.Kaiming初始化
方差一致性:保持数据尺度维持在恰当范围,通常方差为1
激活函数:ReLU及其变种
1 | nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num)) |
1 | nn.init.kaiming_normal_(m.weight.data) |
计算方差变化尺度:
1 | nn.init.calculate_gain(nonlinearity, param=None) |
1 | x = torch.randn(10000) |