Uformer
摘要
Uformer有两个核心结构:
- 局部增强窗transformer结构,采用了基于窗的自注意力机制来降低算力要求,并在前馈网络中采用深度卷积捕获更多局部上下文信息;
- 采用三种skip connection结构将编码器中的信息传递到解码器。实验部分在去噪、去雨、去模糊、去摩尔纹等图像恢复任务上进行了测试。
1.模型结构
Uformer 是 2 个针对图像复原任务 (Image Restoration) 的 Transformer 模型,它的特点是:
- 长得很像 U-Net (医学图像分割的经典模型),有Encoder,有Decoder,且 Encoder 和 Decoder 之间还有 Skip-Connections。
- 在 Transformer 的Block中融合了卷积。
下图是论文种Uformer的架构示意,但是该图不是很直观。
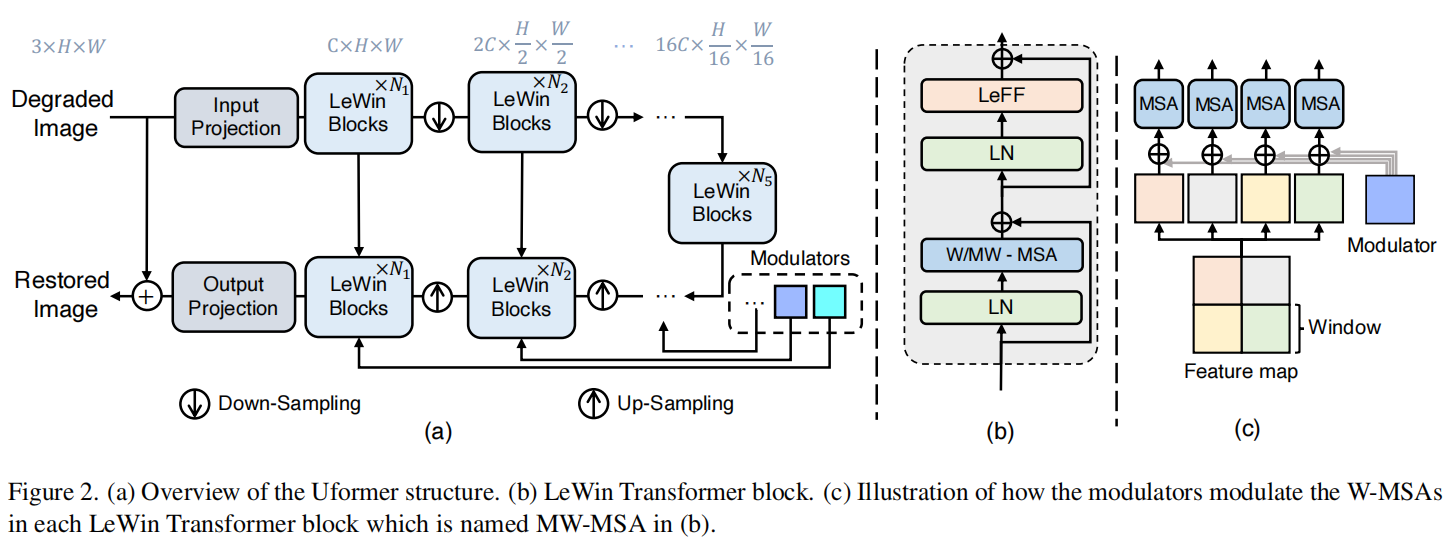
在官方的代码中,提供了更加具体的模型结构示意。作者已经把张量的维度标注在了图里面。
- 整体类似U-Net
- 有Encoder,有Decoder
- Encoder 和 Decoder 之间还有 Skip-Connections连接。
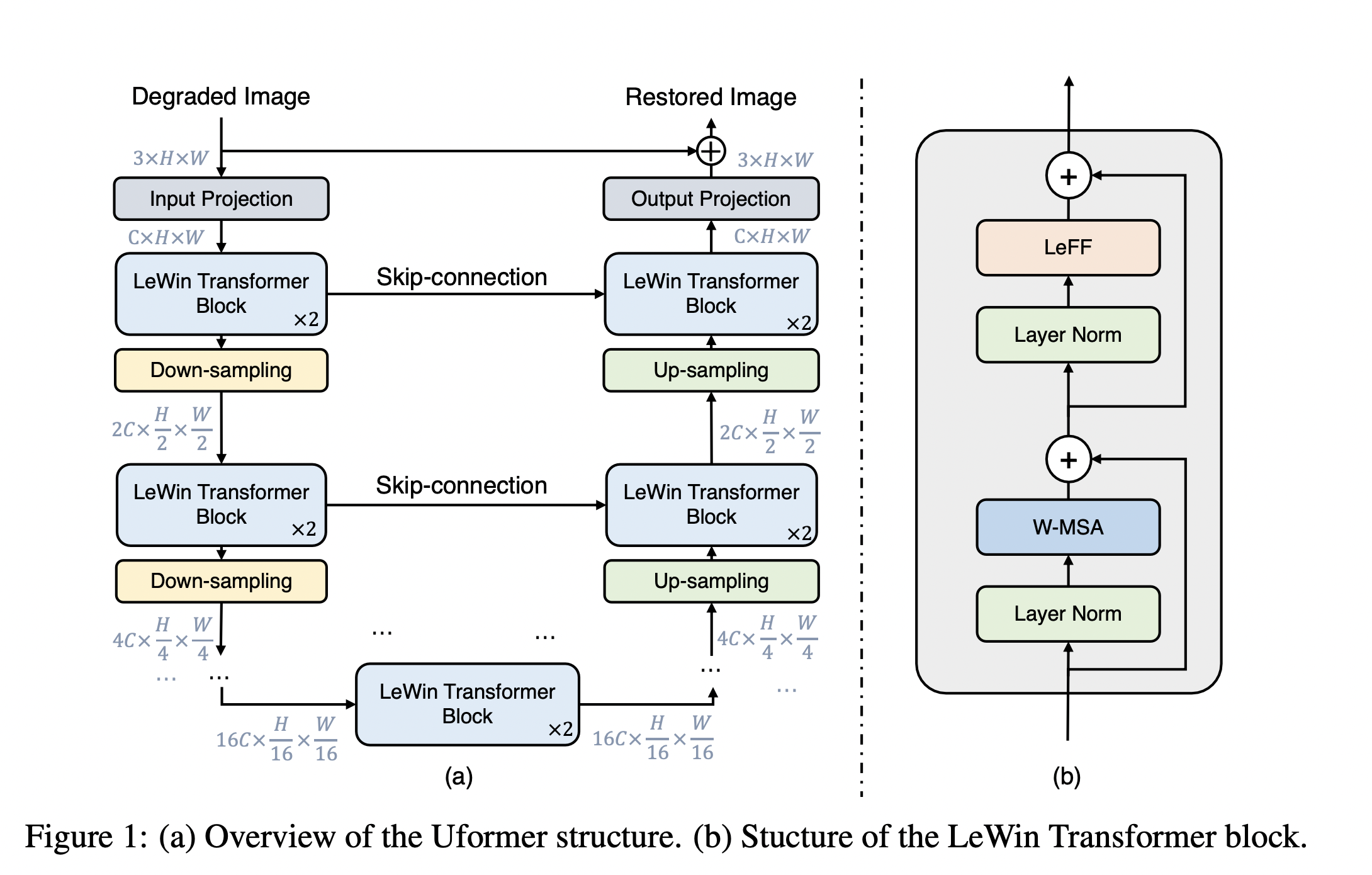
1)卷积提取特征(Input Projection)
第一层卷积层进行底层特征提取,输入一个Degraded Image$\mathbf{I} \in \mathbb{R}^{3 \times H \times W}$,Uformer首先通过$3\times 3$卷积和 LeakyReLU激活函数来提取底层特征,得到$\mathbf{X}_{0} \in \mathbb{R}^{C \times H \times W}$。
2) Encoder:
- 接着$\mathbf{X}_{0} \in \mathbb{R}^{C \times H \times W}$进入U形结构的Encoder部分,一共是$K$个阶段,每个阶段由2个 LeWin Transformer Block 和 1个下采样 Down-sampling 层组成。
- LeWin Transformer Block:首先把张量 reshape成1D的序列特征$\mathbf{X}^{‘} \in \mathbb{R}^{ HW \times C}$,它可以借助 Self-attention 机制的建模长序列信息的能力并通过 non-overlapping windows的办法节约计算量。
- 下采样 Down-sampling 层:首先把张量 reshape成2D的空间特征,再通过一个$k=4,s=2$(步长为2的$4\times 4$)的卷积操作进行下采样,并将通道数加倍。经过这2步以后,第1个stage输出的张量维度是$2C\times \frac{H}{2}\times \frac{W}{2}$,第$l$个stage输出的张量维度是$2^lC\times \frac{H}{2^l}\times\frac{W}{2^l}$。
3) Bottleneck Stage:
- Bottleneck Stage,本质上是通过2个LeWin Transformer Block。
- 编码器的最后一层堆叠多个LeWin transformer块,这些LeWin transformer块可以捕获到长程信息,如果特征图大小和卷积核尺寸相同相当于是全局信息。
4) Decoder:
Decoder 用于特征的重建,一共是$K$个阶段,每个阶段由 1个上采样 Up-sampling 层 2个 LeWin Transformer Block 组成。
- 首先,上采样层也是先把张量 reshape成2D的空间特征,再通过$k=2,s=2$(步长为2,尺寸为$2\times 2$)的 Transposed Convolution(转置卷积) 执行,上采样层处理后分辨率变为4倍,通道数减半。
- 其次,这个上采样后的特征和来自Skip-Connection的 Encoder的特征一起输入 LeWin Transformer Block,通过它来恢复丢失的数据。 $K$个阶段完成以后,通过一个3×3卷积得到Residual Image$\mathbf{R} \in \mathbb{R}^{3 \times H \times W}$。
实验中设置$K=4$,即Encoder和 Decoder都是4个阶段,所以skip-connection有3个,损失函数是Charbonnier loss:
其中,$\hat{\mathbf{I}}$是真实值,$\epsilon=10^{-3}$是微小值。
概括起来,Uformer主要有以下三个部分结构上的两点。
- W-MSA:Window-based Multi-head Self-Attention
- LeFF:Locally-enhanced Feed-Forward Network
- Skip-Connection:(a) Concat-Skip,(b) Cross-Skip, and (c) ConcatCross-Skip.
2.LeWin Transformer Block
两个重要的结论:
- 计算全部 tokens 之间的 attention 是不合适的。对于 Image Restoration 的任务一般都是高分辨率的图片,比如1048×1048的图片,此时得到的patches数量会很多,如果还计算全部 tokens 之间的attention的话,计算量开销会变得很大($O((\text{token})^2)$),显然不合适。
- 每个 patch 的 local 的上下文信息很重要。对于 Image Restoration 的任务local的上下文信息很重要。一个 degraded pixel 的邻近 pixel 可以帮助这个 pixel 完成重建。
所以,提出了locally-enhanced window (LeWin) Transformer block:
- W-MSA:non-overlapping Window-based Multi-head Self-Attention ,窗之间不重叠;
- LeFF:也就是Locally-enhanced Feed-Forward Network (LeFF) 。
因此一个LeWin transformer块的计算如下:
2.1 W-MSA
这个模块是LeWin Transformer Block 的第1步。具体而言,它不使用全部的 tokens 来做 Self-attention,而是在不重叠的局部窗口 (non-overlapping local windows) 里面去做attention,以减少计算量。
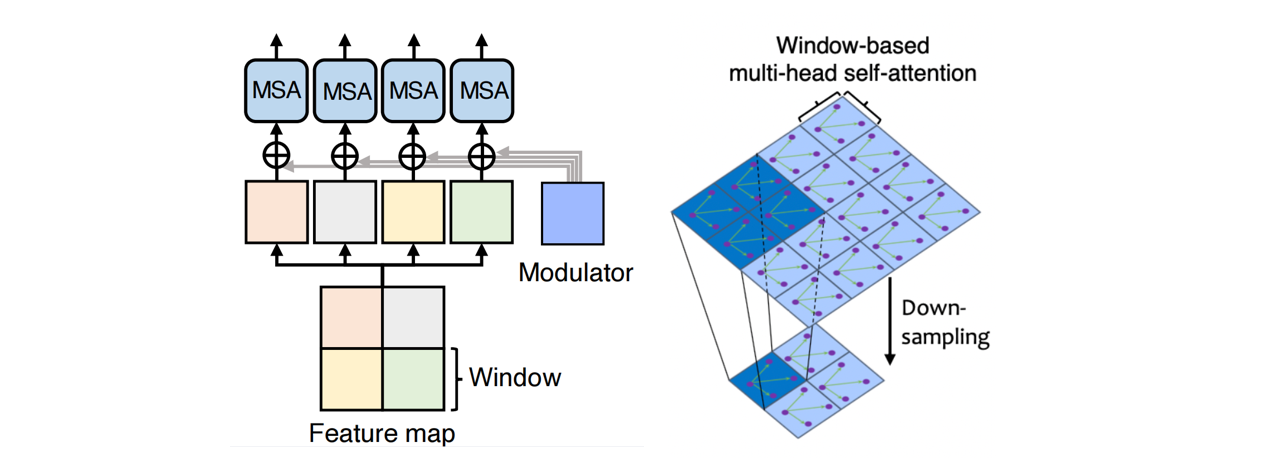
输入2D的特征图$\mathbf{X}_{0} \in \mathbb{R}^{C \times H \times W}$,宽为$H$高为$W$
- 把这个特征图分成大小为$M\times M$的相互不重叠的 windows(如上图我们有16个 windows)
- 将每个窗的图像拉伸为一维,把每个 windows 的张量展平后得到的维度都是$\mathbf{X}^{i} \in \mathbb{R}^{M^2\times C}$。
- 对每个 window 执行 Self-attention。假设 head 的数量是$k$ ,每个 head 的维度是$d_k=C/k$。则计算某个 window 中的第$k$个 self-attention 操作可以写为:
- $\mathbf{X}^i$代表第$i$个window,$\mathbf{Y}_k^i$代表第$i$个window的第$k$个head的结果,$\hat{\mathbf{X}}_{k}$代表第$k$个head的所有windows综合起来的结果。
- $\mathbf{W}_{k}^Q,\mathbf{W}_{k}^K,\mathbf{W}_{k}^V\in \mathbb{R}^{C \times d_k}$分别表示第$k$个head的queries,keys,values的映射矩阵。
在attention module里面仍然采用的是相对位置编码 (relative position encoding),所以attention的表达式为:
式子中,$\mathbf{B}$是相对位置编码,其值来自于可学习的$\hat{\mathbf{B}} \in \mathbb{R}^{(2 M-1) \times(2 M-1)}$矩阵。在输入特征图为$\mathbf{X} \in \mathbb{R}^{C \times H \times W}$,如果使用全局的self-attention,则序列长度为$N=HW$,计算量为$O(H^2W^2C)$,如果使用全局W-MSA,有$\frac{H}{M}\frac{W}{M}$个windows,每个windows的计算量为$M^4C$,所以此时的计算量为$O(M^2HWC)$。同时因为用了层级结构,低分辨率上的自注意力机制就可以获得很大的感受野,足以学习长程信息。
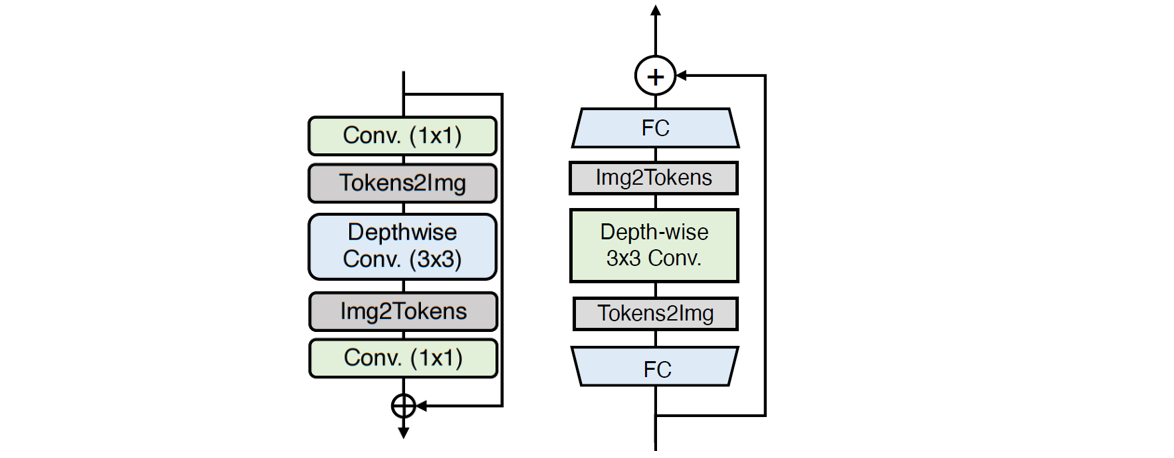
2.2 Leff
- 首先特征通过一个 FC 层来增大特征的维度 (feature dimension),再把序列化的1D特征 reshape 成 2D的特征,并通过 3×3 的 Depth-wise Convolution来建模 local 的信息。
- 再把2D的特征 reshape 成序列化的1D特征,并通过一个 FC 层来减少特征的维度到原来的值,每一个 FC 层或 Depth-wise 卷积层后使用 GeLU 激活函数。
3.Skip-Connection
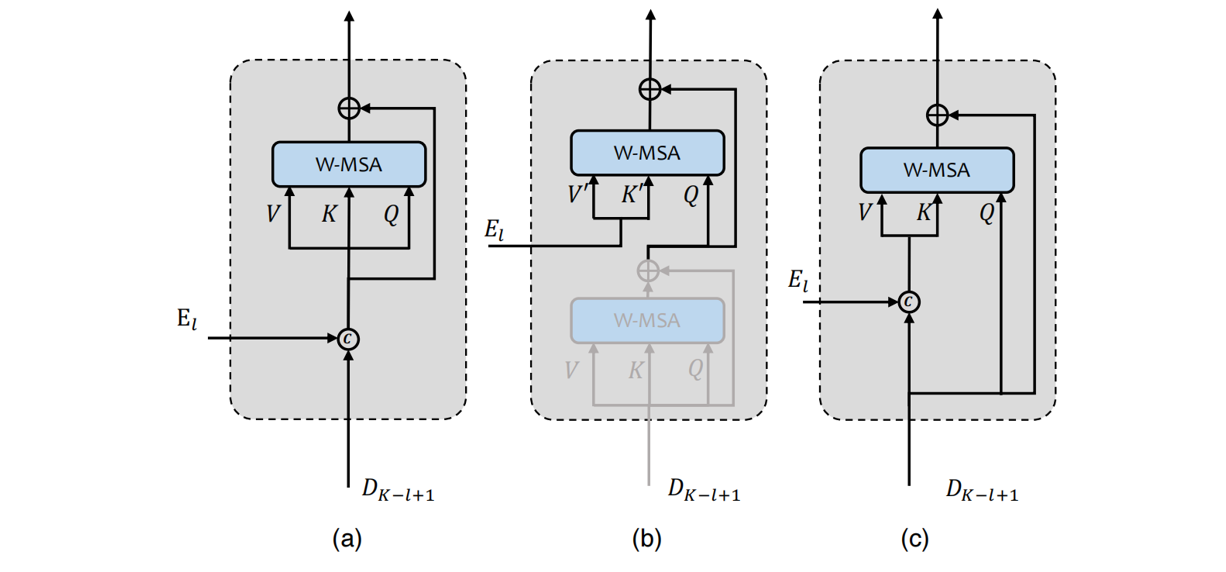
为了研究如何把 Encoder 里面的 low-level 的特征更好地传递给 Decoder,作者探索了3种Skip-Connection的方式。
首先 Decoder 中的每个 LeWin Transformer Block 要综合2方面的信息,其一是来自 Encoder的输出$E_l\in 2^{l-1}C\times \frac{H}{2^{l-1}}\times \frac{W}{2^{l-1}}$,其二是来自Decoder的输出$D_{l-1}\in 2^{l-1}C\times \frac{H}{2^{l-1}}\times \frac{W}{2^{l-1}}$
- Concatenation-based Skip-connection (Concat-Skip):直接把二者在 channel 这个维度给 concatenate 在一起,得到的张量维度是$2^{l}C\times \frac{H}{2^{l-1}}\times \frac{W}{2^{l-1}}$,把它输入给 W-MSA 模块。
- Cross-attention as Skip-connection (Cross-Skip):给Decoder阶段的每个 LeWin Transformer block 里面加一个额外的attention module,这个 attention module 的 query 是第1个W-MAS的输出,key 和 value 都是$E_l$
- Concatenation-based Cross-attention as Skip-connection (Concat Cross-Skip):把二者在 channel 这个维度给 concatenate 在一起,且W-MSA 的query 是$D_{l-1}$,key 和 value 都是 concat 后的结果。
4.实验
4.1实验设置
- 优化器:AdamW
- momentum:0.9,0。999
- weight decay:0.02
- 数据增强:horizontal flipping,旋转90°,180°,270°。
- 学习率变化策略:cosine decay strategy
- 初始学习率:2e-4,变化到1e-6。
- window size:8×8,则一个 window 是8×8的,一个wendow的序列长度是64。
- Evaluation metrics:PSNR 和 SSIM。