CVbaseline-VGG
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
1.论文研究背景、成果及意义
ILSVRC:大规模图像识别挑战赛
ImageNet Large Scale Visual Recognition Challenge 是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展
比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)
竞赛中脱颖而出大量经典模型: alexnet,vgg,googlenet,resnet,densenet等
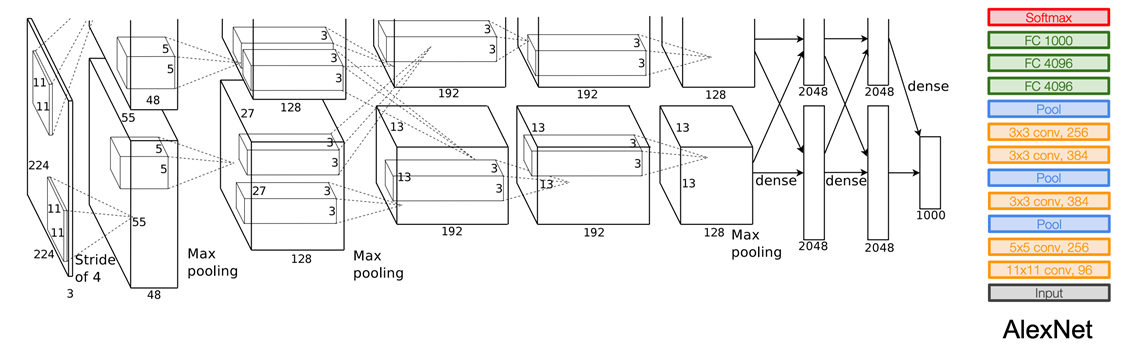
1.AlexNet:ILSVRC-2012分类冠军,里程碑的CNN模型
2.ZFNet: ILSVRC-2013分类冠军方法,对AlexNet改进
3.OverFeat:ILSVRC-2013定位冠军,集分类、定位和检测于一体的卷积网络方法
| 模型 | 时间 | top-5-error |
|---|---|---|
| AlexNet | 2012 | 15.3% |
| ZFNet | 2013 | 13.5% |
| VGG | 2014 | 7.3% |
相关研究
1.AlexNet:ILSVRC-2012分类冠军,里程碑的CNN模型
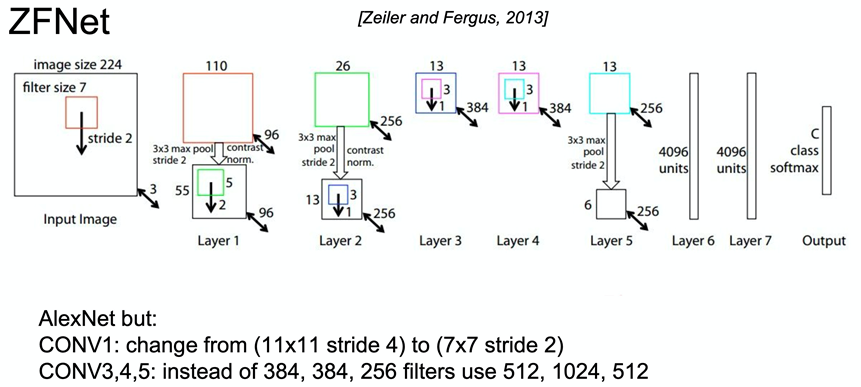
2.ZFNet: ILSVRC-2013分类冠军方法,对AlexNet改进(改变了超参数的设置)。卷积核的数目更小,对AlexNet进行参数的改进,具体改进如图所示:
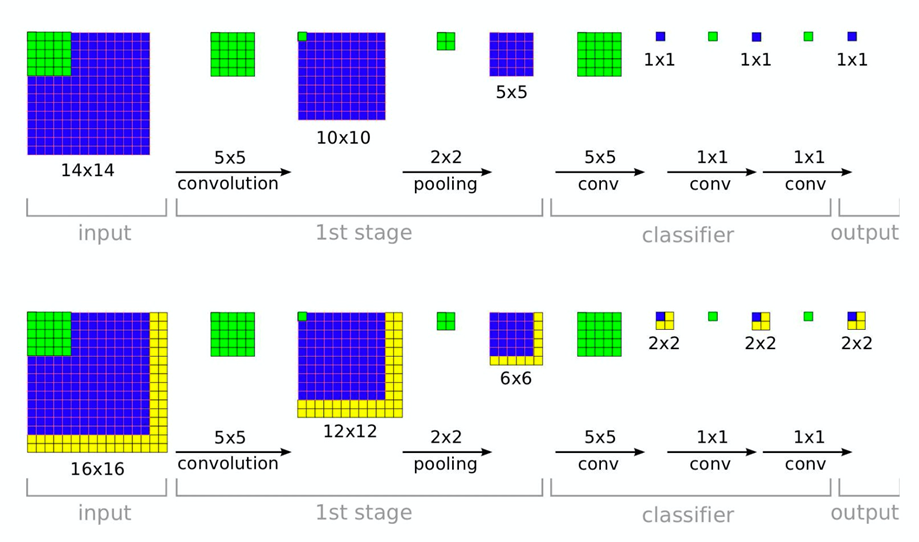
3.OverFeat:ILSVRC-2013定位冠军,集分类、定位和检测于一体的卷积网络方法,提出了全卷积的方式进行参数的预测。(全卷积)
可以在一次运算内实现多裁剪。【只需要输入一张图片】
1.AlexNet:借鉴卷积模型结构
2.ZFNet: 借鉴其采用小卷积核思想
3.OverFeat:借鉴全卷积,实现高效的稠密(Dense)预测
4.NIN:尝试$1*1$卷积(network in network)
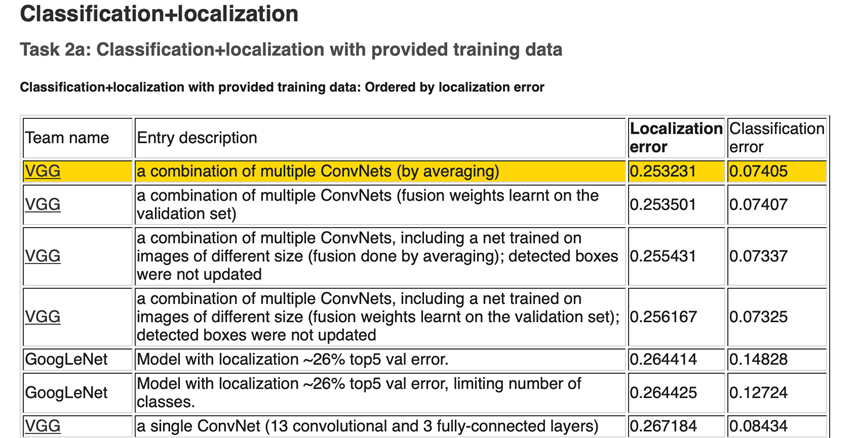
VGG-ILSVRC成绩
VGG:定位第一名,分类第二名
GoogLeNet:分类第一名,定位第二名
研究意义
1.开启小卷积核时代:$3*3$卷积核成为主流模型
2.作为各类图像任务的骨干网络结构:分类、定位、检测、分割一系列图像任务大都有VGG为骨干网络的尝试。
2.摘要核心
本文主题:在大规模图像识别任务中,探究卷积网络深度对分类准确率的影响
主要工作:研究卷积核增加网络模型深度的卷积网络的识别性能,同时将模型加深到16-19层
本文成绩:VGG在ILSVRC-2014获得了定位任务冠军和分类任务亚军
泛化能力:VGG不仅在ILSVRC获得好成绩,在别的数据集中表现依旧优异
开源贡献:开源两个最优模型,以加速计算机视觉中深度特征表示的进一步研究
3.VGG结构
共性:
5个maxpool池化层,降低分辨率。
maxpool后,特征图通道数翻倍直至512。
3个FC层进行分类输出。
maxpool之间采用多个卷积层堆叠,对特征进行提取和抽象。
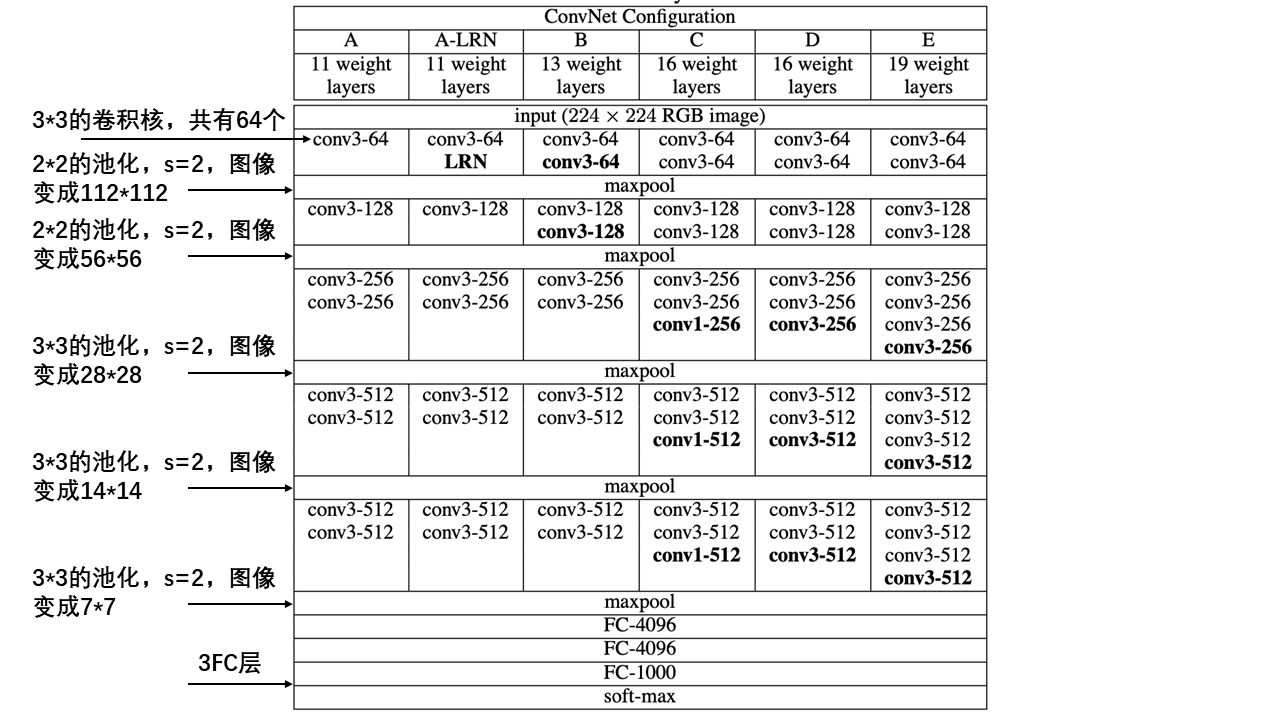
演变过程:
- A:$1\times1$层卷积
- A-LRN:基于A增加一个LRN
- B: 第1,2个block中增加1个卷积$3\times3$卷积
- C:第3, 4, 5个block分别增加1个$1\times1$卷积,增加了模型的非线性能力,$1\times1$卷积的思路来自于NIN,表明增加非线性有益于指标提升
- D(VGG16):第3, 4, 5个block的$1\times1$卷积替换为$3\times3$,
- E(VGG19):第3, 4, 5个block再分别增加1个$3\times3$卷积
参数设置:
模型改进过程中,参数量并没有明显的变化:
原因:FC(全连接层)占据主要的参数,之前的层数增加对总参数的影响比较小。
| Network | A A-LRN | B | C | D | E |
|---|---|---|---|---|---|
| Number of parameters | 133 | 133 | 134 | 138 | 144 |
VGG16结构:

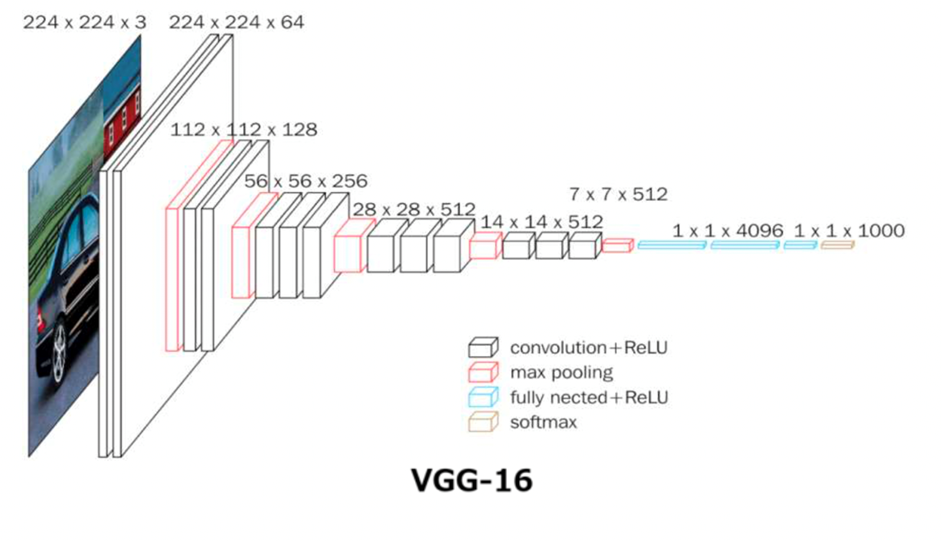
4.VGG特点
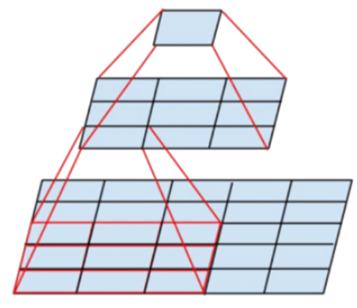
(1)堆叠$3*3$卷积核
- 增大感受野,2个$3\times3$堆叠等价于1个$5\times5$,如图所示:
3个$3\times3$堆叠等价于1个$7\times7$
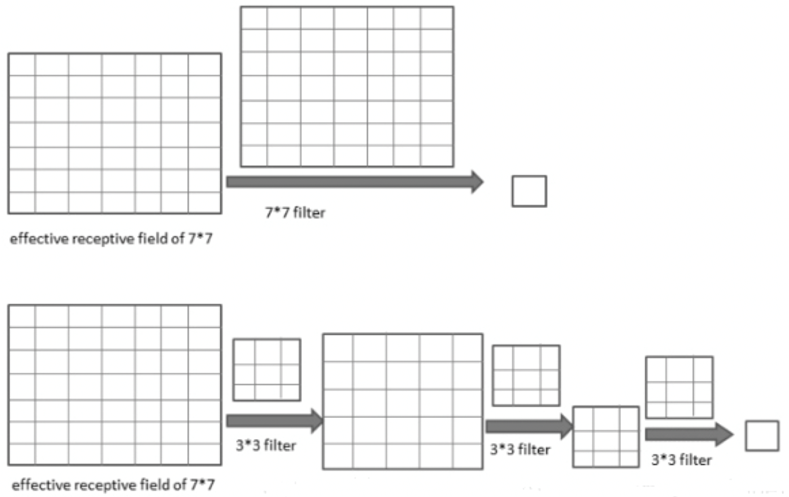
- 增加非线性激活函数,增加特征抽象能力
- 减少训练参数
- 可看成$7\times7$卷积核的正则化,强迫$7\times7$分解为$3\times3$
假设输入,输出均为$C$个通道:
- 一个$7\times7$卷积核所需要的参数量:$7\times7\times c\times c=49C^2$
- 三个$3\times3$卷积核所需要的参数量:$3\times(3\times3\times C\times C)=27C^2$
- 参数减少比:44%

(2)尝试卷积:借鉴NIN,引入利用卷积,增加非线性激活函数,提升模型效果。

5.训练技巧
5.1尺度扰动
数据增强
方法一:针对位置/尺寸
训练阶段:
- 按比例缩放图片至最小边为$S$
- 随机位置裁剪出$224*224$区域
- 随机进行水平翻转
方法二:针对颜色
修改RGB通道的像素值,实现颜色扰动
S设置方法:
1.固定值:固定为256,或384
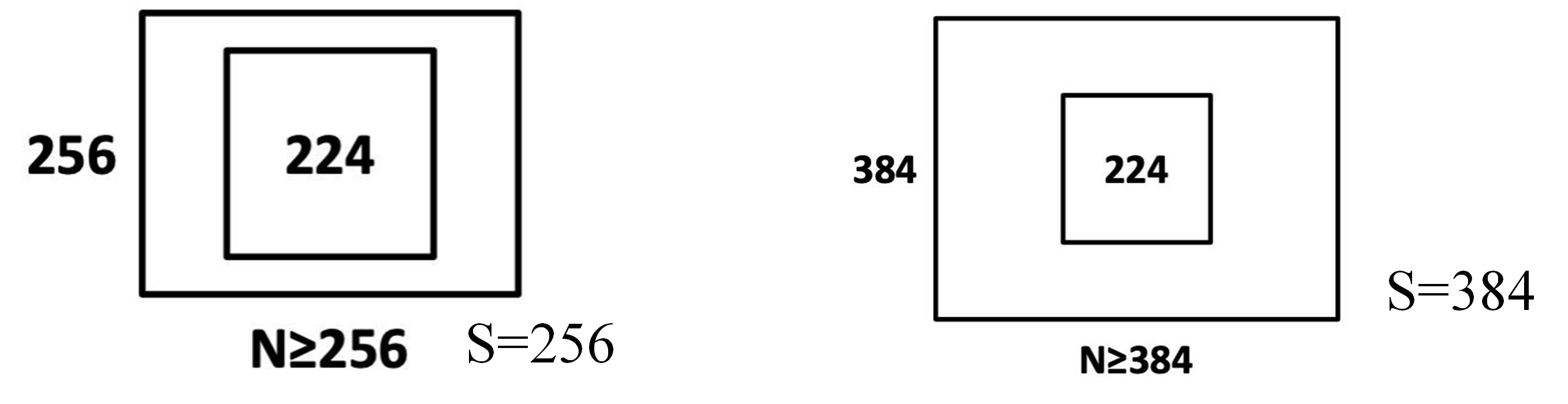
2.随机值:每个batch的$S$在[256, 512],实现尺度扰动(multi-scale training)
5.2预训练模型
预训练模型初始化
深度神经网络对初始化敏感
1.深度加深时,用浅层网络初始化:B,C,D,E用A模型初始化
2.Multi-scale训练时,用小尺度初始化
- $S=384$时,用$S=256$模型初始化
- $S=[256, 512]$时,用$S=384$模型初始化
3.直接使用Xavier初始化方法。
6.测试技巧
多尺度测试:
图片等比例缩放至最短边为$Q$,设置三个$Q$,对图片进行预测,取平均值。
方法1:当$S$为固定值时,$Q=[S-32,S,S+32]$
方法2:当$S$为随机值时,$Q=[S_{\min},0.5\times(S_{\min}+S_{\max}),S_{\max}]$
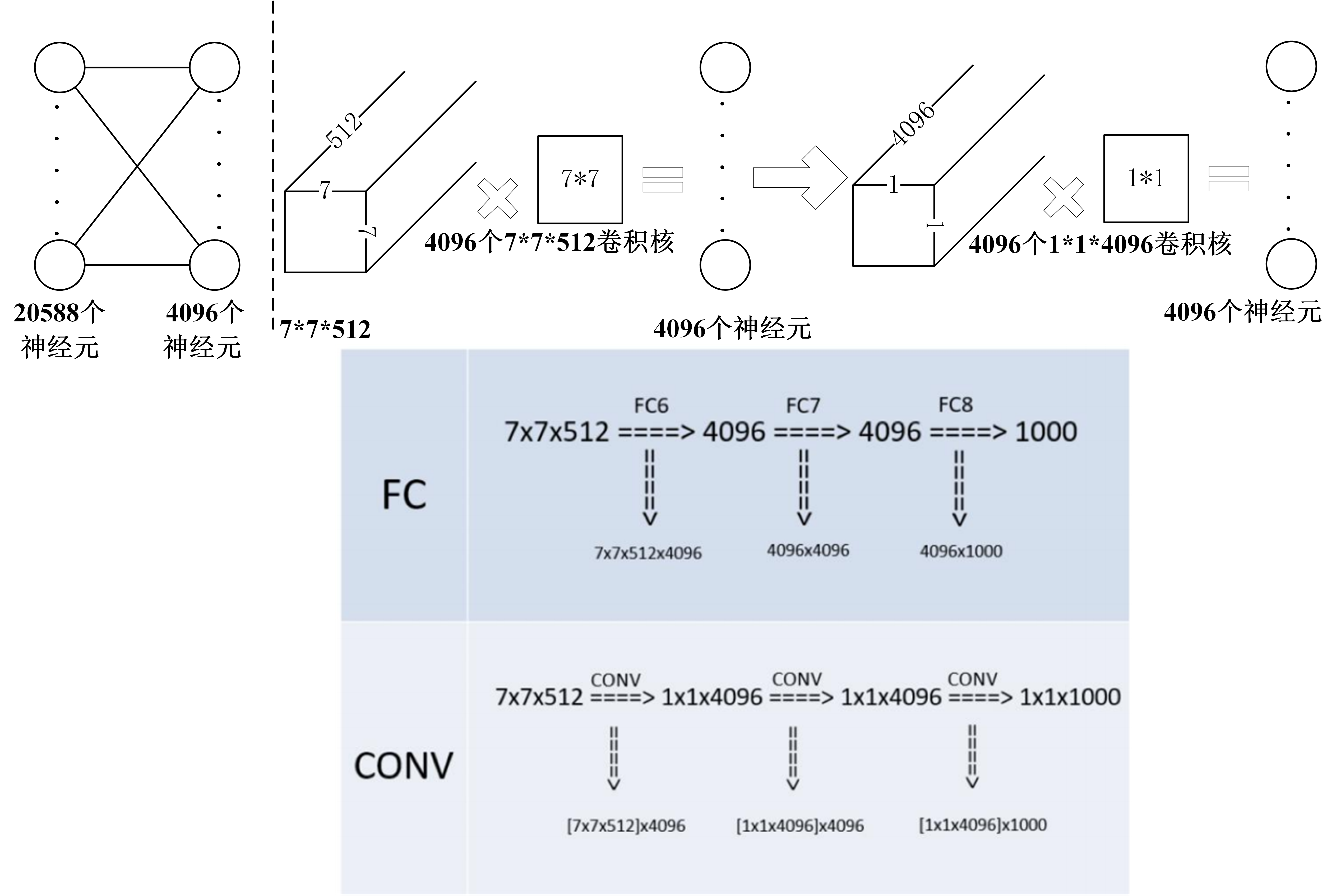
6.1Dense测试
稠密测试(Dense test):将FC层转换为卷积操作,变为全卷积网络,实现任意尺寸图片输入。
- 经过全卷积网络得到 $N\times N\times1000$ 特征图
- 在通道维度上求和(sum pool)计算平均值, 得到$1\times1000$ 输出向量(在上图中,下面这种情况,最后会在$2\times2\times1000$上进行平均得到$1\times1\times1000$)。
6.2Multi-crop测试
Multi-Crop测试 :借鉴AlexNet与GoogLeNet,对图片进行Multi-crop,裁剪大小为$224\times224$,并水平翻转1张图,缩放至3种尺寸,然后每种尺寸裁剪出50张图片50 = $5\times5\times2$
多尺度测试:
step1:等比例缩放图像至三种尺寸, $Q_1,Q_2,Q_3$
step2:
方法1 Dense:全卷积,sum pool,得到$1*1000$
方法2 Multi-crop:多个位置裁剪$224\times224$区域
方法3 Multi-crop & Dense:综合取平均
7.结果分析
1.Single scale evaluation
结论:
- 误差随深度加深而降低,当模型到达19层时,误差饱和,不再下降
- 增加$1*1$有助于性能提升
- 训练时加入尺度扰动,有助于性能提升
- B模型中,$3\times3$替换为$5\times5$卷积,top1下降7%
2.Multi scale evaluation
方法1 : $Q = [S-32, S, S+32]$
方法2:$Q = (S_\min, 0.5\times(S_\min + S_\max), S_\max)$
结论:测试时采用Scale jittering有助于性能提升。
3.Multi crop evaluation
方法: 等步长的滑动$224\times224$的窗口进行裁剪,在尺度为Q的图像上裁剪$5\times5=25$张图片,然后再进 行水平翻转,得到50张图片,结合三个$Q$值,一张图片得到150张图片输入到模型中。
结论:
- multi-crop由于Dense
- multi-crop结合Dense,可以形成互补,达到最优效果。
4.Convnet fusion
ILSVRC中提交的模型为7个模型融合
采用最优的两个模型
- D/[256,512]/256,384,512
- E/[256,512]/256,384,512
结合multi-crop和dense,得到最优结果。
8.总结
- 采用小卷积核,获得高精度
- 采用多尺度及稠密预测,获得高精度
- $1\times1$卷积可认为是线性变换,同时增加非线性层
- 填充大小准则:保持卷积后特征图分辨率不变
- LRN对精度无提升
- Xavier初始化可达较好效果
- $S$远大于224,图片可能仅包含物体的一部分
- 大尺度模型采用小尺度模型初始化,可加快收敛
- 物体尺寸不一,因此采用多尺度训练,可以提高精度
- multi crop 存在重复计算,因而低效
- multi crop可看成dense的补充,因为它们边界处理有所不同
- 小而深的卷积网络优于大而浅的卷积网络
- 尺度扰动对训练和测试阶段有帮助
9.核心代码实现
pytorch中的VGG定义
1 | import torch |
VGG16的定义:
1 | def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs): |
1 | def make_layers(cfg, batch_norm=False):#定义各个层 |
定义网络结构:
1 | vgg16_model = vgg16() |

可以观察到VGG的网络结构:
1 | VGG( |
使用torchvision可以方便的定义VGG网络,甚至可以修改某一层的结构:
1 | import torchvision.models as models |