1.列表list
1.1 列表生成
列表是由一系列特定元素组成的,元素和元素之间没有任何关系,但他们之间有先后顺序的关系
列表是一种容器—列表是序列的一种—列表是可以被改变的序列
- 创建空列表的字面值:
1 | L = [ ]#绑定空列表 |
- 创建非空列表:
1 | L = [1,2,3,4] |
列表的构造:
list( )生成一个空的列表 等同于[ ]list(iterable)用可迭代对象创建一个列表
1 | a = [1,1,None,1,[1,2],'sda',4,print] |

1.2 列表的运算
- 算术运算:
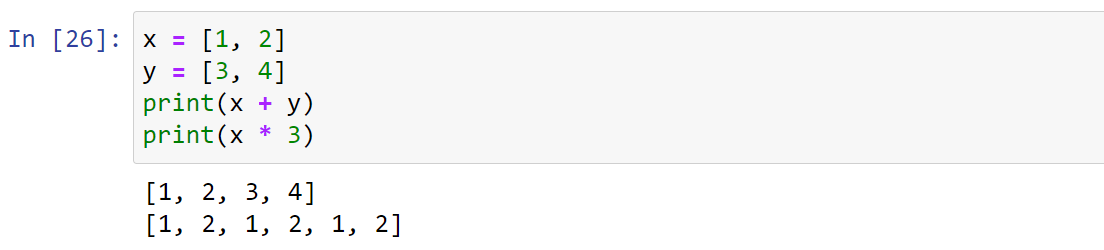
+用于拼接列表+=用于原列表左侧可迭代对象进行拼接,生成新的列表*用于生成重复的列表*=用于生成重复的列表,同时用变量绑定新列表in/not in判断一个数据元素是否存在于容器(列表)
- 列表的索引/切片:index/slice
- 列表的索引语句:
列表[整数表达式] - 用法:列表的索引取值与字符串的索引取值规则完全相同。列表的索引分为正向索引和反向索引
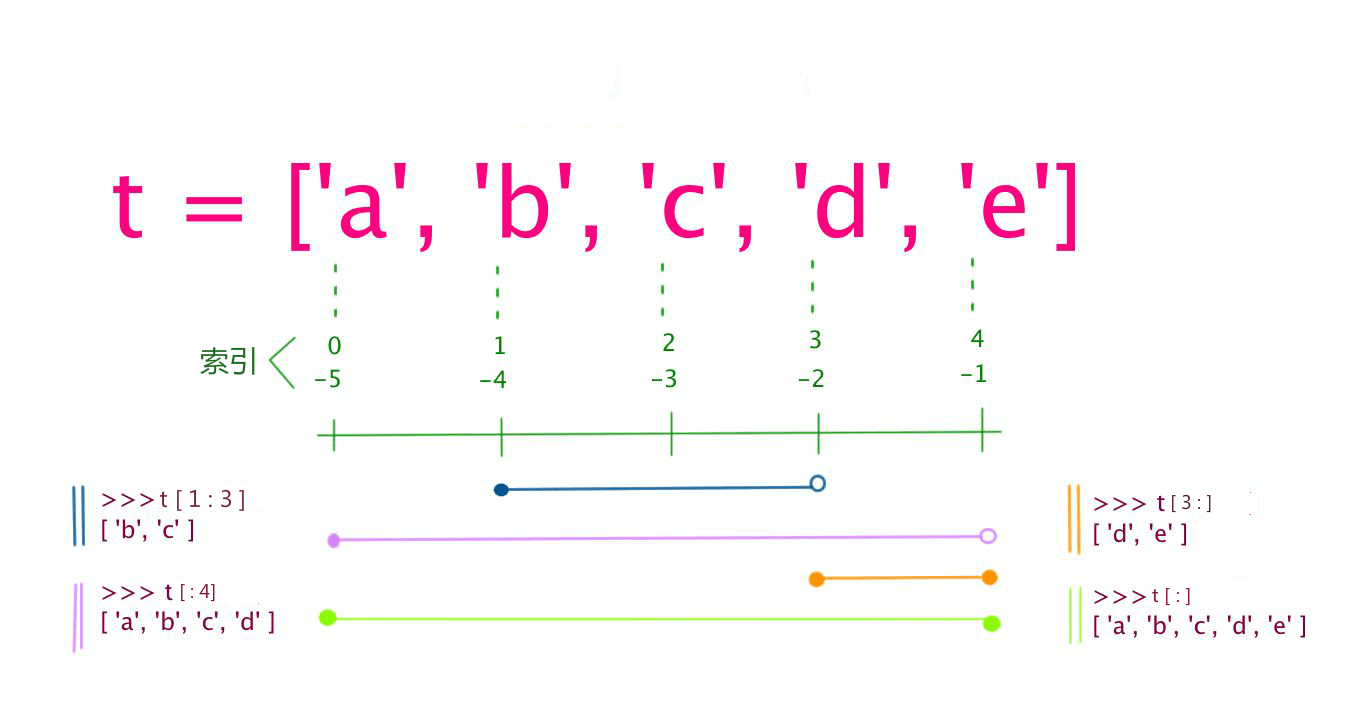
- 列表的索引语句:
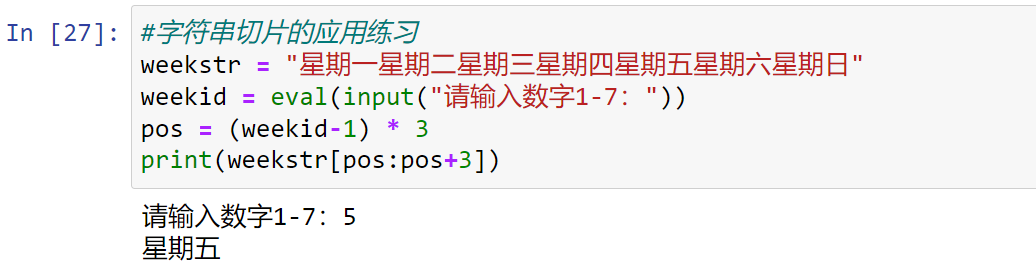
1 | #字符串切片的应用练习 |
- 列表的索引赋值操作:
- 列表是可变的序列,可以通过索引赋值改变列表元素
- 语法:
列表[索引] = 表达式
1 | #实现修改字符串中某个位置的元素的方法 |

- 列表的切片:
- 列表
[:] - 列表的
[::] - 列表的切片取值返回一个列表,规则等同于字符串的切片规则
- 列表

- 列表切片的赋值语法:
列表[切片]=可迭代对象- 说明:切片赋值的赋值运算的右侧必须是一个可迭代对象
1 | # 说明:切片赋值的赋值运算的右侧必须是一个可迭代对象! |
- del语句:用于删除列表元素
- 语法:
del 列表[索引]或者del 列表[切片]
- 语法:
1.3 列表函数
常用的序列函数:
len(x)返回序列长度max(x)返回序列中最大值元素min(x)返回序列中的最小值元素sum(x)返回序列中所有元素的和(元素必须是数值类型)any(x)真值测试,如果列表中其中有一个值为真值,则返回True,否则返回Falseall(x)真值测试,如果列表中所有值为真值,则返回True,只要有一个为假,则返回False
列表方法:
l.index(v[,begin[,end]])返回对应元素的索引下标,begin为开始索引,end为结束索引,当value不存在时触发ValueError错误l.insert(index,obj)将某个元素查房到列表中指定的位置l.count(x)返回列表中的元素的个数l.remove(x)从列表中删除第一次出现在列表中的值l.copy()复制此列表(只复制一层,不会复制深层对象)l.append(x)向列表中追加单个元素l.extend(list)向列表中追加一个列表l.clear()清空列表,等同于l[:]=[]l.sort(reverse=false)将列表中的元素进行排序,默认值按值的由小到大的顺序排l.reverse()列表的反转,用来改变原列表的先后顺序l.pop([index])删除索引对应的元素,如果不加索引,默认删除最后的元素,同时返回删除元素
字符串文本解析方法
1 | s.split(sep=None) |
1 | print('1 2 3 4 5 6 7\n8\t9'.split(' ')) |

1.4 深浅拷贝
深拷贝(deep copy)和浅拷贝(shallow copy):
浅拷贝:是指在赋值过程中只复制一层变量,不会复制深层变量绑定对象的复制过程
1 | L = [3.1,3.2] |
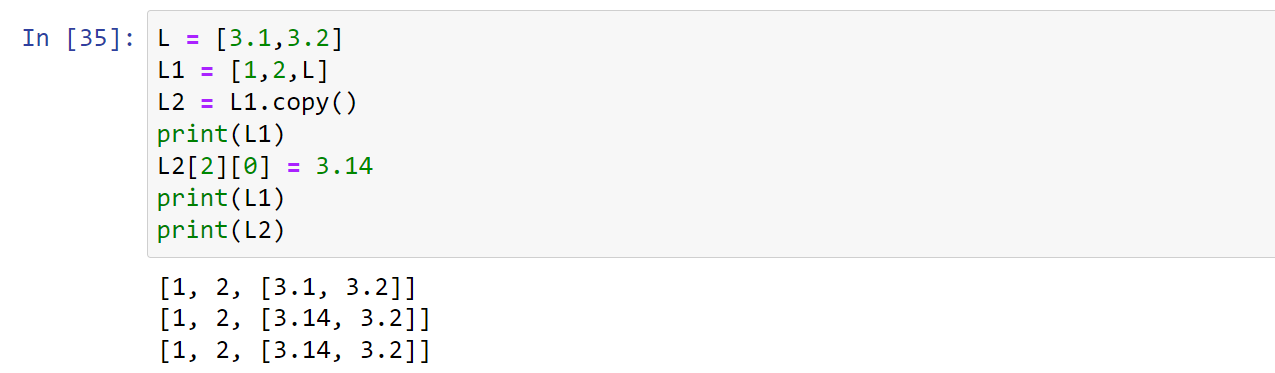
深拷贝:通常只对可变对象进行复制,不可变对象通常不变
1 | import copy |
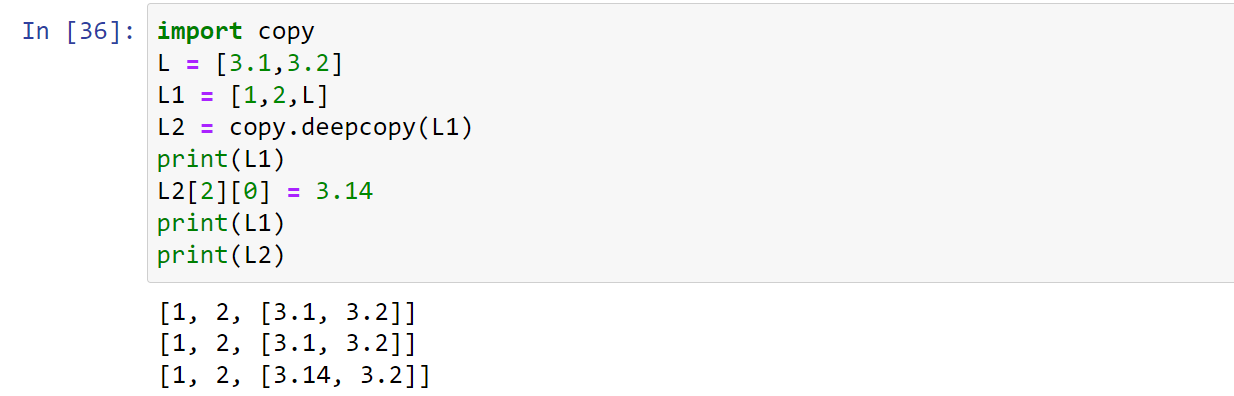
=是深拷贝
1 | A = ['apple'] |

[:]是浅拷贝
1 | A = ['apple'] |

1.5 列表推导式
列表推导式是用可迭代对象依次生成带有多个元素的列表的表达式
作用:用简易的方法生成列表
语法:
[表达式 for 变量 in 可迭代对象][表达式 for 变量 in 可迭代对象 if 真值表达式]

列表表达式的嵌套:
1 | [表达式1 |
1 | print([m + n for m in 'ABC' for n in 'XYZ']) |

与其他容器混合使用:
1 | d = {'x': 'A', 'y': 'B', 'z': 'C' } |

与if-else语句嵌套使用
1 | print([x if x % 2 == 0 else -x for x in range(1, 11)]) |

1.6 列表生成器
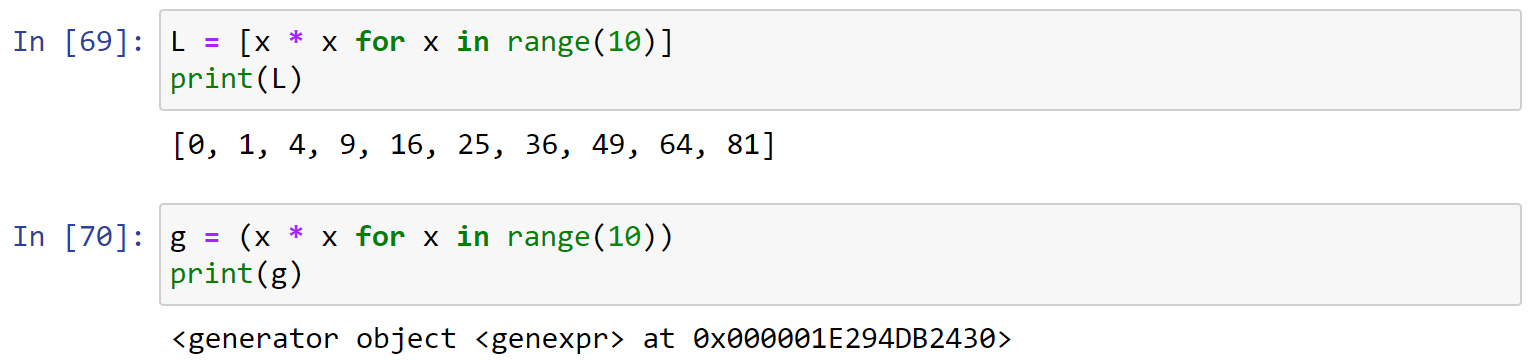
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
1 | g = (x * x for x in range(2)) |
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
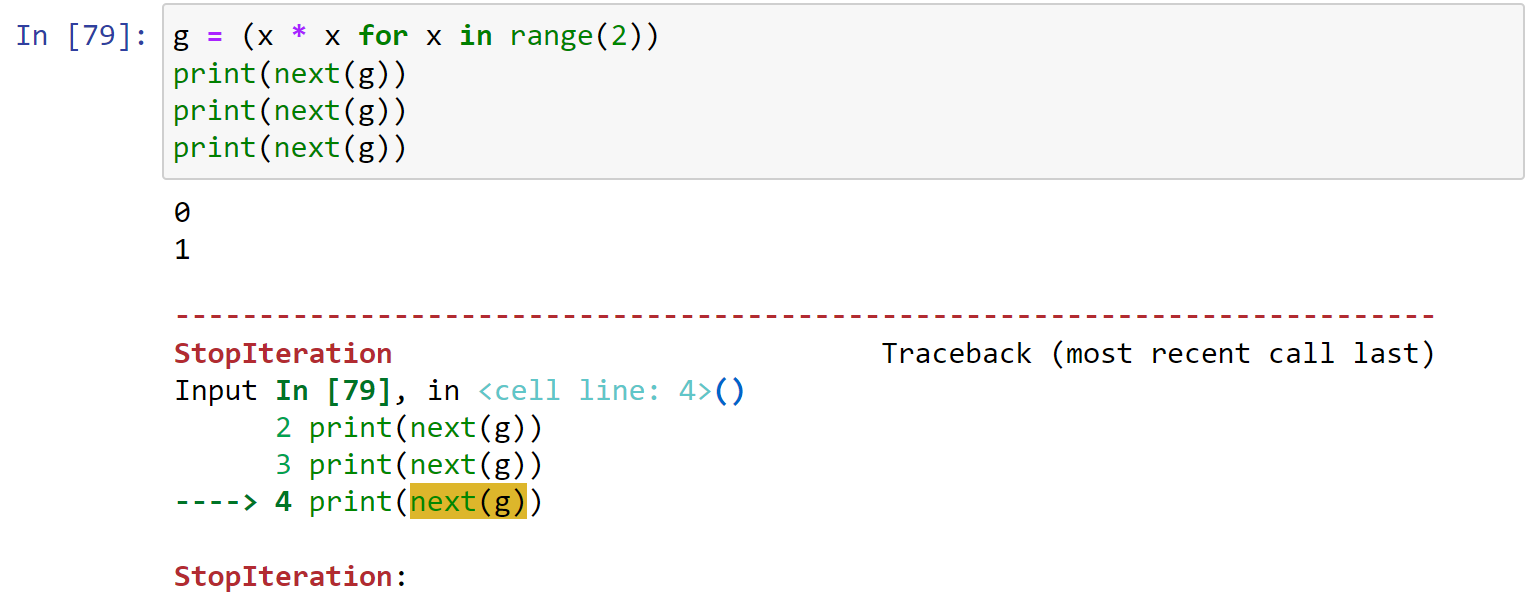
使用for语句调用列表生成器:
1 | g = (x * x for x in range(3)) |

如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator函数,调用一个generator函数将返回一个generator:
1 | def test(): |

调用generator函数会创建一个generator对象,多次调用generator函数会创建多个相互独立的generator。
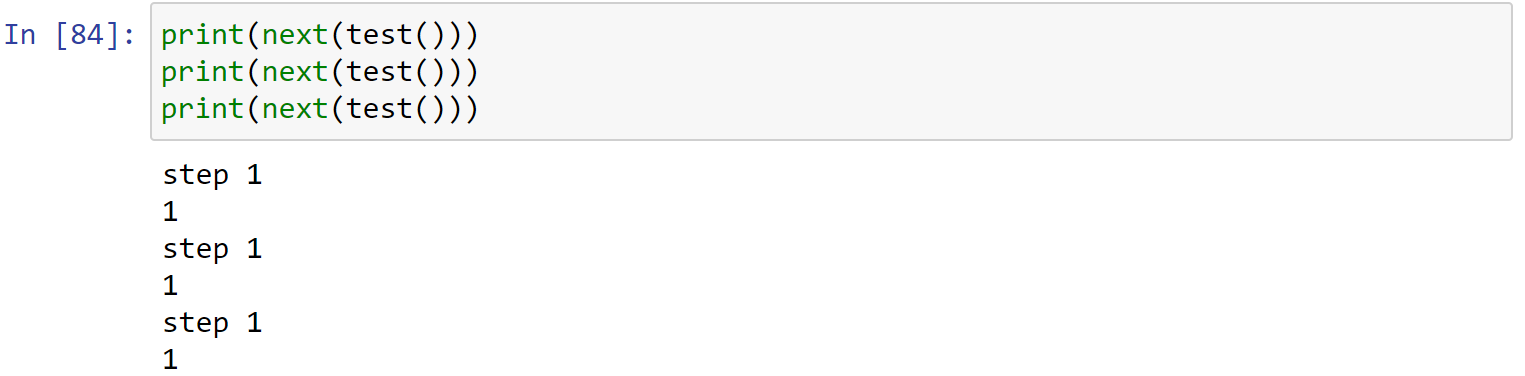
所以,需要预先定义好generator对象:
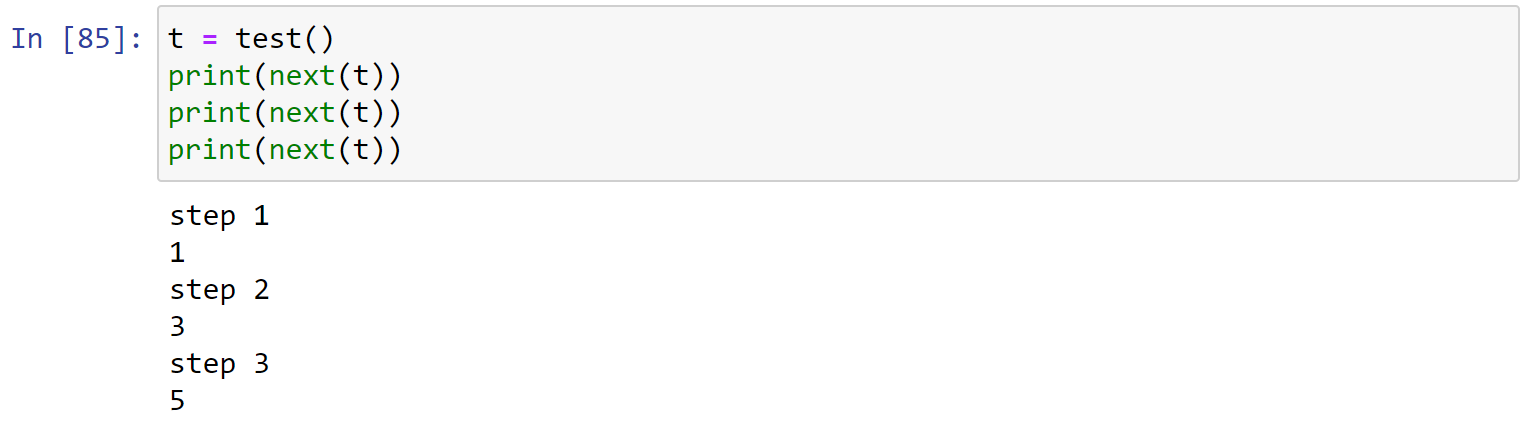
1.7 列表解包
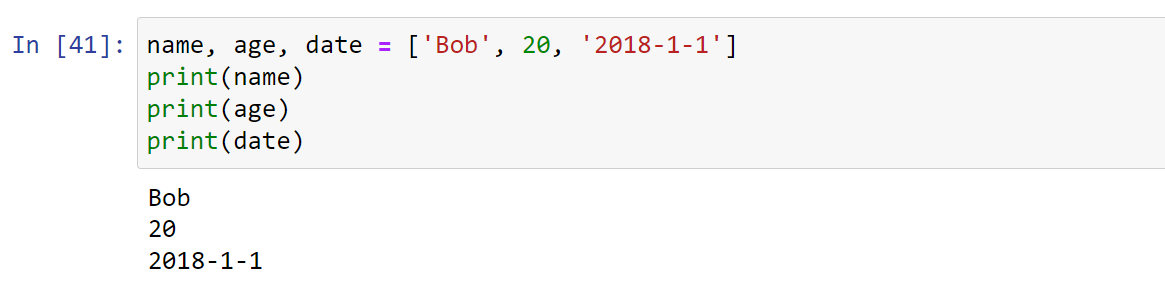
将list中每个元素赋值给一个变量
1 | name, age, date = ['Bob', 20, '2018-1-1'] |
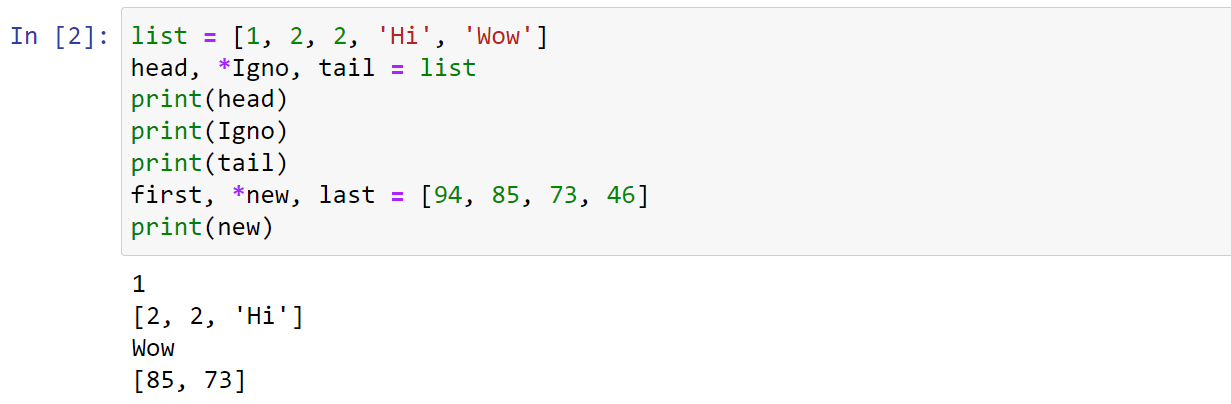
使用*:比如我们要计算平均分,去除最高分和最低分,除了用切片,还可以用解包的方式获得中间的数值。
1 | list = [1, 2, 2, 'Hi', 'Wow'] |
压包和解包混合:
1 | l = [('Bob', '1990-1-1', 60), |

_的用法
当一些元素不用时,用_表示是更好的写法,可以让读代码的人知道这个元素是不要的

1.8 列表迭代
1 | from collections.abc import Iterable |

Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
1 | for i, value in enumerate(['A', 'B', 'C']): |

2.元组tuple
2.1 元组生成
- 元组是不可改变的序列,同list一样,元组可以存放任意类型的元素,一旦元组生成,则它不可以改变
- 元组的表达方式:用小括号
( )括起来,单个元素括起来用逗号(,),区分是单个对象还是元组,创建空元组的字符值t=( ) - 元组的构造函数 tuple
tuple( )生成一个空的元素,等同于( )tuple(iterable)用可迭代对象生成一个元组
1 | t = tuple() |

- 元组的算术运算:
+ += * *= < <= > >= == !=规则与列表完全相同 in/in not索引取值/切片取值—规则与列表完全相同- 区别:元组是不可变对象,不支持索引赋值和切片赋值
2.2 元组的方法
1 | t.index(v[,begin[,end]]) |
可用于序列的函数:len,max,min,sum,all,any
三个构造函数:
str(obj) list(iterable) tuple(iterable)用于创建相应的对象
其他函数:
1 | reversed(seq)返回反向顺序的可迭代对象 |
3.字典dict
- 字典是一种可变的容器,可以储存任意类型的数据
- 字典中的每个数据都是用’键’(key)进行索引,而不像序列可以用下标进行索引
- 字典的数据没有先后顺序,字典的存储是无序的
- 字典中的数据以键(key)-值(value)对进行映射存储
- 字典的键不能重复,而且只能用不可变类型作为字典的键
字典的字面值表示方式:{ }括起来,以冒号:分隔键值对,各键值对用分号隔开。
3.1 字典的构造
创建空字典:
1 | d={ } |
创建非空的字典:
1 | d = {'name':'tarena';'age':15} |
len()函数是统计键值对的个数- 集合之间的显示是随机的,输出时不一定按照原有的顺序进行输出
字典的构造函数 dict
dict( )创建一个空字典,等同于{ }
dict(iterable)用可迭代对象初始化一个字典
dict(**kwargs)关键字传参形式生成一个字典
1 | d = dict( ) |
只要是有两个数之间的对应关系都可以输出,分别作键和值
1 | d = dict(("AB","CD")) |

字典的键是不可变类型:int float complex bool str tuple frozenset(字节串) bytes(字节串)
3.2 字典的基本操作
1)用[]运算符可以获取字典内的’键’对应的’值’
语法: 字典[键]
1 | d = {'first':123, 'second':456} |

2)添加/修改字典元素
字典[键]=表达式- 当键存在时就修改键对应的值,如果不存在则创建键值对
3)del语句删除字典中的元素
语法:del 字典[键]
字典的方法:
1 | d.clear()清空字典 |
字典推导式:字典推导式是用可迭代对象依次生成字典内元素表达式
语法:{键值表达式:值表达式 for 变量 in 可迭代对象 [if 真值表达式]}
注:[ ]内的内容可以省略
1 | L=['tarena','xiaozhang','xiaowang'] |

1 | a = dict(); |

格式化输出
1 | library = [('Author','Topic','Pages'),('Alex','Soccer',200),('Raj','Golf',18),('Tony','Tik Tok',1005)] |
4.集合set
- 集合是可变的容器,集合内的对象是唯一的,集合是无序的存储结构,集合中的数据没有先后关系,集合内的元素必须是不可变的对象,集合是可以迭代的,集合是相当于只有键没有值的字典(键则是集合的数据)
- 创建空的集合:
set() - 创建非空集合:
s={1,2,3} - 集合的构造函数 set
set()创建空集合set(iterable)用可迭代对象创建一个新的集合对象
4.1 集合的运算
交集,并集,补集,子集,超集
1 | &用于生成两个集合的交集 |
4.2 集合的处理方法
1 | s.add(e)向集合中添加一个新元素e,如果元素已经存在,则不添加 |
4.3 集合推导式
用可迭代对象来创建(生成)集合表达式
语法:
1 | {表达式 for 变量 in 可迭代对象 [if 真值表达式]} |
4.4 固定集合
固定集合:frozenset
固定集合是不可变的,无序的,含有唯一元素的集合
作用:固定集合可以作为字典的键,也可以作为集合的值
1)创建空的固定集合 fs=frozenset()
2)创建非空的固定集合 fs=frozenset()
构造函数:frozenset() frozenset(可迭代对象)(返回固定集合)
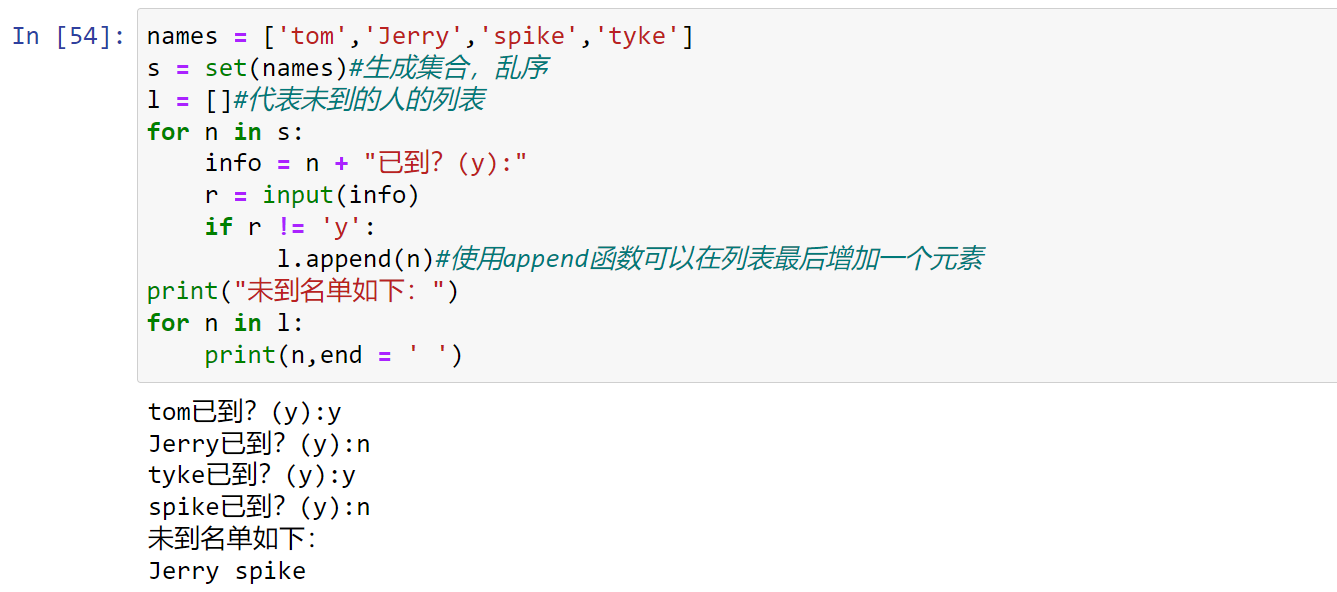
【案例制作】
小练习:模拟一个点名系统,已知全班同学的名单,随机打印学生的名字,点名结束后打印未到名单
1 | names=['tom','Jerry','spike','tyke'] |